注意力机制:让模型学会抓重点,从查询、键、值到Transformer
一、为什么模型需要注意力?
1. 人类本来就会“挑重点”
想象你在一个热闹的集市里找朋友。周围有很多人、很多声音、很多招牌,但你不会把每个细节都完整记住。你会先盯住对方的衣服颜色、站姿、招手动作,快速缩小范围。
这就是注意力。
注意力机制的核心,不是“记住全部”,而是“根据当前任务,决定该关注什么”。
2. 传统模型的问题:总想平均分配注意力
很多早期模型遇到一段输入时,容易把所有位置看成差不多重要。这样做有两个问题:
信息太多时,会被噪声淹没。
距离太远的关键信息,模型不一定能及时抓住。
比如翻译一句话时,英文单词和中文词语之间经常不是一一对应的。如果模型只按固定顺序往前读,遇到长句就容易“前面忘了,后面又来不及看”。
注意力机制就是为了解决这个问题而生的:让模型在需要的时候,动态回头看更相关的内容。
3. 一个很直白的比喻:查字典
你要查“卷积”这个词时,会先在目录里找“卷”或“convolution”附近的条目。
你的目的,就是查找现在真正想要的内容,这叫 查询(Query)。
每个词条都有自己的名字、标签、索引,这些像 键(Key)。
真正的词条解释内容,像 值(Value)。
模型也是同样的思路:
Query:我现在想解决什么问题
Key:每个候选信息的“标签”
Value:被取出来的真实内容
注意力机制做的事,就是先比较 Query 和每个 Key 的相关程度,再把对应的 Value 按重要性加权汇总。
二、注意力提示:模型该往哪看?
1. 生物学里的注意力提示
在现实世界里,注意力不是随机发生的,而是会被一些“提示”触发。
比如:
你听到自己的名字,会立刻抬头。
你看到红色警示牌,会比普通文字更敏感。
你在做数学题时,会更在意数字、符号和条件,而不是题干里的背景故事。
这些能引导注意力的线索,就叫 注意力提示。
2. 查询、键和值:注意力机制的三件套
这是注意力机制最重要的一组概念。
| 名称 | 通俗理解 | 作用 |
|---|---|---|
| Query | 我现在想找什么 | 发出需求 |
| Key | 每条信息的标签 | 用来比较相关性 |
| Value | 这条信息真正的内容 | 被加权汇总 |
你可以把它想成“在商场里找商品”:
Query 是你心里想买的东西。
Key 是每个货架贴的商品标签。
Value 是货架上真正的商品。
模型先看 Query 和 Key 像不像,再决定从哪些 Value 多拿一点。
3. 注意力其实就是加权平均
如果只说一句话,注意力机制可以概括成:
先算每个位置的重要性,再做加权平均。
数学上可以写成:
output=sumialphaivioutput = sum_i alpha_i v_ioutput=sumialphaivi
其中:
alphaialpha_ialphai 表示第 iii 个位置的权重
viv_ivi 表示第 iii 个位置的值
权重越大,这个位置对结果影响越大。
4. 一个生活化例子
假设你在读一句话:
小明把苹果放进了冰箱,因为它很容易坏。
这里“它”指的是“苹果”,而不是“冰箱”。
如果模型想判断“它”指谁,就不能平均看前文所有词,而应该更关注“苹果”这个词。注意力机制做的,就是这种“把目光投向更相关词语”的工作。
5. 注意力的 可视化
注意力不是神秘黑箱。我们通常可以把权重画成热力图,看看模型到底在关注哪里。
比如在 机器翻译 里:
译“我喜欢这本书”时,模型可能会重点关注“喜欢”和“书”。
译长句时,某个中文词可能会对应英文里的几个词。
可视化的价值很大,因为它能帮我们回答一个很实际的问题:
模型是“真的看懂了”,还是只是碰巧猜对了?
三、注意力汇聚:Nadaraya-Watson 核回归
注意力机制并不是先有 深度学习 才出现的。其实早在 1964 年,人们就在统计学习里用过一个非常接近注意力思想的方法:Nadaraya-Watson 核回归。
它的思想特别适合入门理解,因为它几乎就是“注意力机制的雏形”。
1. 先看最简单的平均汇聚
如果你想预测一个点的值,最偷懒的方法就是平均周围样本。
比如周围 5 个点分别是:2、4、6、8、10。
直接平均就是 6。
这就是平均汇聚:不管远近,不管相似不相似,大家权重都一样。
这个方法简单,但太粗糙了。因为离你更近、更像你的样本,往往更值得参考。
2. 非参数注意力汇聚:相似的多看,不相似的少看
Nadaraya-Watson 的核心做法是:
先看当前输入和每个样本有多像。
越像的样本,权重越大。
最后把所有样本的值加权平均。
这就像你在问同学题目答案时:
跟你学得差不多的人,建议更可信。
完全不在一个水平的人,参考价值就低一些。
所以它不是简单平均,而是根据相似度分配权重。
3. 一个最小示例
下面是一个非常小的示意代码,帮助你理解“权重越大,越像被重点关注”。
import torch def attention_pooling(query, keys, values): # query: 当前想预测的位置(一个标量或向量) # keys: 所有候选样本的位置(与 query 同类型的张量) # values: 候选样本对应的真实值(将被加权汇总) # 下面计算每个 key 与 query 的相似性得分:这里用负平方距离,距离越小得分越大 scores = -((keys - query) ** 2) # 把得分转换为概率权重,softmax 会把所有分数规范化为正数并使其和为 1 weights = torch.softmax(scores, dim=0) # 用权重对 values 做加权求和,得到注意力汇聚结果;同时返回权重便于可视化或调试 return (weights * values).sum(), weights # --- 示范用法 --- # 构造一个示例查询(query)和值/键(keys, values) query = torch.tensor(2.5) # 我们想预测的位置是 2.5 keys = torch.tensor([1.0, 2.0, 3.0, 4.0]) # 四个候选位置 values = torch.tensor([1.0, 2.0, 3.0, 4.0]) # 对应的真实值(这里简单用位置本身作为示例) # 调用注意力汇聚函数得到输出和每个候选的权重 output, weights = attention_pooling(query, keys, values) # 打印结果:output 是汇聚后的预测值,weights 是每个候选被关注的程度 print('output =', output) print('weights =', weights)
这里的重点不是代码多复杂,而是思路:
先算 query 和每个 key 的相关性。
再把相关性变成权重。
最后对 values 做加权求和。
这和现代注意力机制的主干完全一致。
4. 带参数的注意力汇聚
前面的方法里,相关性是“手工定义”的,比如距离越近权重越大。
但真实问题里,我们希望模型自己学会什么叫“相似”。于是就会引入参数,让模型自动学习权重怎么分配。
这样一来,注意力不再是固定公式,而是一个可以训练的模块。
这就是从“统计里的核回归”走向“深度学习里的注意力层”的关键一步。
5. 小结
Nadaraya-Watson 核回归告诉我们一件很重要的事:
模型不一定要平均看待所有输入,它可以根据相关程度,给不同输入不同权重。
这就是注意力思想的原点。
四、注意力评分函数:先打分,再汇总
注意力机制的核心流程可以拆成三步:
计算 Query 和 Key 的相关性。
把相关性变成权重。
对 Value 做加权求和。
第一步最关键,因为“怎么打分”,会直接影响注意力怎么分配。
1. 掩蔽 softmax:有些位置不能看
在很多任务里,并不是所有位置都能看。
比如:
句子补齐后的空白部分,不能被当成真实词语。
在生成文本时,模型不能偷看未来词,只能看已经生成的过去词。
这时候就要用 掩蔽 softmax。
它的作用很简单:
不允许看的位置,分数直接设成一个极小值。
这样经过 softmax 后,这些位置的权重就接近 0。
可以把它理解成“黑名单机制”。
2. 加性注意力:用一个小网络来打分
加性注意力的思路是:
把 Query 和 Key 拼在一起。
送进一个小神经网络。
输出一个相关性分数。
通俗理解:
不只是看“像不像”,还让模型自己学会“怎么判断像不像”。
这类方法通常比较灵活,适合处理 Query 和 Key 维度不同的情况。
3. 缩放点积注意力:更直接、更高效
另一种非常常见的方法是 缩放点积注意力。
它的打分方式很直接:
score=(q⋅k)/sqrt(d)score = (q \cdot k) / sqrt(d)score=(q⋅k)/sqrt(d)
其中:
qqq 是 Query
kkk 是 Key
ddd 是向量维度
为什么要除以 sqrt(d)sqrt(d)sqrt(d)?
因为维度越大,点积数值越容易变得很大,softmax 就会变得特别“偏激”,容易只盯住某一个位置。缩放以后,训练会更稳定。
4. 什么时候用哪种?
你可以这样记:
加性注意力:更灵活,适合不一样的 Query 和 Key。
缩放点积注意力:更简单、更快,Transformer 里最常见。
5. 小结
注意力评分函数就像“打分器”。
先给每个候选信息打分,再把分数变成权重,最后汇总值。
这件事看起来普通,但它是所有注意力模型的共同骨架。
五、Bahdanau 注意力:让翻译模型学会“回头看”
如果说前面的内容是在讲“注意力是什么”,那 Bahdanau 注意力就是注意力机制真正进入深度学习主流的代表作之一。
它最早在机器翻译任务里大放异彩。
1. 传统 Seq2Seq 的问题
早期的编码器-解码器模型,通常会把整句输入压缩成一个固定长度的向量,再交给解码器生成翻译。
这个做法的问题很明显:
短句还行。
长句容易丢信息。
就像你把一整本书压缩成一张便签,再指望它帮你复述全文,难度太大了。
2. Bahdanau 注意力的思路
Bahdanau 注意力的关键改进是:
解码器在生成每一个词时,都可以回头看编码器输出的全部位置,并决定当前最该关注哪里。
也就是说,翻译不是一次性看完整句就结束,而是每一步都重新分配注意力。
3. 直白理解:翻译时边写边查
你可以把它想成写作文时查资料:
写到这一句时,你会回头翻前面的笔记。
下一句又可能参考另外一页。
每一步关注的位置都可能不一样。
Bahdanau 注意力做的,就是这种“边生成,边回看”的事情。
4. 结构上发生了什么?
最简单地说:
编码器把输入句子变成一串隐藏状态。
解码器当前的状态作为 Query。
编码器每个时间步的隐藏状态作为 Key 和 Value。
计算注意力权重后,得到一个上下文向量。
解码器用这个上下文向量去生成下一个词。
5. 一个小示意图

这个循环会一直重复,直到整句翻译完成。
6. 训练时要注意什么?
Bahdanau 注意力本身是可微分的,所以可以直接用反向传播训练。
训练时通常会配合 teacher forcing,也就是:
训练阶段,把上一时刻的真实词语喂给解码器。
推理阶段,模型自己根据上一步的预测继续往下生成。
7. 小结
Bahdanau 注意力最重要的价值,不只是“翻译效果变好了”,而是它证明了:
模型可以在生成过程中动态对齐输入和输出。
这一步非常关键,因为它让注意力真正成为了序列建模的核心工具。
六、多头注意力:一个人看不够,就让很多人一起看
1. 为什么要多头?
单个注意力头,通常只能从一个角度看问题。
但真实语言往往很复杂:
有的词关系是主谓关系。
有的词关系是修饰关系。
有的词关系隔得很远。
如果只用一种关注方式,模型很可能看漏。
所以就有了 多头注意力。
2. 多头注意力的直观理解
你可以把它想成开会:
一个同学负责看主语和谓语。
一个同学负责看修饰词。
一个同学负责看长距离依赖。
最后大家把结论汇总起来。
这比一个人从头看到尾更稳。
3. 多头到底做了什么?
多头注意力通常包含以下步骤:
把输入投影到多个子空间。
每个子空间单独做一次注意力。
把多个头的结果拼接起来。
再做一次线性变换。
这样模型就能同时从多个角度“读同一句话”。
4. 一个简单的比喻
如果单头注意力像一副望远镜,那么多头注意力就像:
一组不同焦距的望远镜
一起看同一个目标
有的看细节,有的看全局。
5. 多头的好处
表达能力更强。
能学到不同类型的关系。
更适合复杂序列任务。
6. 小结
多头注意力的核心思想其实很朴素:
让多个注意力模块并行工作,每个模块负责看不同的“重点”。
这也是 Transformer 之所以强大的关键组件之一。
七、自注意力和位置编码:同一句话里,词语彼此交流
1. 什么是自注意力?
前面我们讲的注意力,常常是“一个输入去关注另一个输入”。
而 自注意力 更直接:
同一个序列里的每个位置,都会去关注同一序列里的其他位置。
也就是说,句子里的每个词,都可以“和自己队伍里的其他词开会”。
比如在句子“我把书放在桌子上”里:
“放”可能会关注“书”和“桌子”。
“桌子”可能会关注“上”。
“书”可能会关注“放”。
于是,每个词都能拿到一个融合了上下文的新表示。
2. 自注意力为什么强?
它有三个很明显的优点:
可以并行计算,不像 RNN 那样必须一步一步读。
能直接建立远距离依赖,不需要层层传递。
表达灵活,能根据任务动态决定关注谁。
3. 和 CNN 、RNN 比一比
| 模型 | 主要特点 | 优点 | 局限 |
|---|---|---|---|
| CNN | 局部感受野,擅长看邻近区域 | 计算高效,局部特征强 | 远距离依赖需要多层堆叠 |
| RNN | 按顺序读取序列 | 自然适合时间序列 | 难并行,长距离信息容易衰减 |
| 自注意力 | 序列内部任意位置都能互相看 | 全局建模强,并行能力好 | 没有位置编码时,不知道顺序 |
如果只看这一张表,你就已经抓住了自注意力的主线:
它强在“全局看、并行算、动态选重点”。
4. 但它也有一个天然问题:不知道顺序
注意力机制本身只会算“谁和谁相关”,但它并不知道谁在前、谁在后。
如果你把“我爱你”和“你爱我”的词都打乱,单靠注意力很难判断顺序差异。
所以我们还需要 位置编码。
5. 位置编码:给每个位置发一个“座位号”
位置编码就是给序列里的每个位置加上一个表示“我在第几个”的信息。
这样模型就不只知道“有哪些词”,还知道“这些词的先后顺序”。
经典的正弦位置编码可以理解成:
低维度变化快,容易区分相邻位置。
高维度变化慢,帮助模型感知更远的距离。
6. 一个简化版代码示意
import torch def positional_encoding(num_positions, num_hiddens): # 初始化一个全零张量,形状为 (1, 序列长度, 隐藏维度) X = torch.zeros((1, num_positions, num_hiddens)) # positions 是每个位置的索引,形状为 (num_positions, 1) positions = torch.arange(0, num_positions).reshape(-1, 1) # div_term 用于控制不同维度正弦/余弦函数的频率 # 这里按照论文做法,在偶数和奇数维上使用不同的频率比例 div_term = torch.exp( torch.arange(0, num_hiddens, 2) * (-torch.log(torch.tensor(10000.0)) / num_hiddens) ) # 偶数维用 sin,步长为 2(0::2),把 positions 与频率相乘后取 sin X[0, :, 0::2] = torch.sin(positions * div_term) # 奇数维用 cos,步长为 2(1::2) X[0, :, 1::2] = torch.cos(positions * div_term) # 返回位置编码张量,通常会加到输入的词嵌入上 return X # --- 示范用法 --- pe = positional_encoding(6, 8) # 生成长度为 6、隐藏维度为 8 的位置编码 print('positional encoding shape =', pe.shape) # 打印形状以验证输出:应为 (1, 6, 8)
你不用死记这段代码,只要记住一句话:
位置编码是在告诉模型:这些词虽然同时出现,但它们的顺序不能乱。
7. 小结
自注意力负责“看内容关系”,位置编码负责“看顺序信息”。
两者合在一起,模型才真正知道一句话是什么、先后顺序又是什么。
八、Transformer:只靠注意力,也能搭起强大系统
1. Transformer 为什么重要?
2017 年,Transformer 一出现,就把很多序列任务的规则改写了。
它最大的特点是:
不靠循环,主要靠注意力。
这意味着它既能并行处理,又能建模长距离关系,还特别适合大规模训练。
2. Transformer 的整体结构
最经典的 Transformer 可以分成两部分:
编码器(Encoder):把输入句子编码成更有信息的表示。
解码器(Decoder):根据编码结果逐步生成输出。
你可以把它想成“读题 + 写答案”:
编码器负责读懂题目。
解码器负责一步步写答案。
3. 一个 Transformer 块里有什么?
每个基本模块通常包括:
多头注意力
基于位置的前馈网络
残差连接
层规范化
这几样东西组合起来,让模型既能学关系,又能保持训练稳定。
4. 基于位置的前馈网络:给每个位置再加工一次
注意力负责“把信息聚合起来”,前馈网络负责“把每个位置再加工一遍”。
你可以把它理解成:
注意力像开会,把有用信息汇总出来。
前馈网络像个人复盘,把自己的理解再提炼一次。
5. 残差连接和层规范化:训练稳定的关键
深层网络最怕什么?
怕信号传不过去,怕训练不稳定。
所以 Transformer 里要加:
残差连接:让信息可以“绕一下路”直接传过去。
层规范化:让每层输出别太极端,训练更稳。
它们就像给模型装上减震器和旁路通道。
6. 解码器为什么要“看未来”被禁止?
在生成任务里,模型不能提前偷看后面的词。
比如你在写句子时,不能先看到答案再写过程。为了保证训练和生成逻辑一致,解码器里的自注意力会用掩蔽机制屏蔽未来位置。
这就是为什么 Transformer 解码器里有 masked self-attention。
7. 训练时发生什么?
训练 Transformer 时,通常还是用交叉熵损失。
步骤可以非常直白地理解成:
编码器读入源句子。
解码器根据已知前缀预测下一个词。
和真实答案比对,算损失。
反向传播更新参数。
8. Transformer 的优势和代价
优势:
并行能力强。
长距离建模好。
结构统一,容易扩展。
代价:
自注意力计算量随序列长度增长很快。
序列很长时,显存和算力压力会变大。
也就是说,它很强,但并不是“没有代价的万能钥匙”。
9. 一张总览图
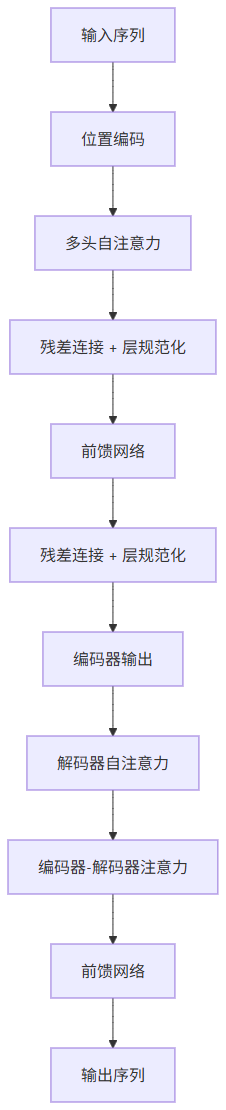
如果你把这个图看懂了,Transformer 的主线就基本抓住了。
10. 小结
Transformer 的真正厉害之处,不是某一个小技巧,而是它把以下几件事整合到了一起:
注意力
多头并行
位置编码
残差连接
层规范化
最后形成了一个既能表达复杂关系、又能高效训练的通用架构。
九、把整章串起来:注意力机制到底在解决什么?
如果用一句话总结整章,那就是:
注意力机制让模型学会根据当前任务,动态决定“看哪里、看多少、怎么看”。
它不是替代所有模型,而是给模型增加了一种非常重要的能力:有选择地处理信息。
你可以把整章内容串成一条线:
注意力提示告诉我们,模型可以像人一样先抓重点。
Nadaraya-Watson 说明了“按相关性加权”的原始思想。
评分函数把“相关性”变成可计算、可训练的权重。
Bahdanau 注意力让序列模型能边生成边回看。
多头注意力让模型从多个角度同时看问题。
自注意力让序列内部的信息彼此交流。
位置编码补上顺序信息。
Transformer 把这些部分组合成一个强大的通用架构。
这就是从“会关注”到“善于关注”的完整演化。
十、给新手的记忆法
如果你刚学这一章,不用一口气背完所有公式。先记住下面这几句就够了:
Query 是我现在想找什么。
Key 是每条信息的标签。
Value 是真正要取走的内容。
注意力就是先打分,再加权平均。
多头注意力就是让多个“关注视角”一起工作。
自注意力是序列内部自己和自己交流。
位置编码是给模型补上顺序感。
Transformer 是只靠注意力搭起来的强大架构。
只要这几句话在脑子里站稳了,后面看论文、看代码、看实现都会顺很多。
十一、练习一下
你可以先不写代码,直接尝试回答这几个问题:
为什么注意力机制比“平均看所有输入”更聪明?
Query、Key、Value 三者分别像什么?
为什么翻译长句时,Bahdanau 注意力比早期 Seq2Seq 更有优势?
多头注意力为什么不是“重复计算”,而是“多角度建模”?
为什么自注意力需要位置编码?
Transformer 里的残差连接和层规范化,分别在帮什么忙?
如果你能用自己的话把这些问题讲出来,说明你已经真正入门了。

