在本指南中,我们将探索如何使用 o1 模型(特别是 o1-preview)通过推理执行数据验证。我们将介绍一个涉及合成医疗数据集的实际示例,并演示如何评估模型在识别数据中问题的准确性。
概述
数据验证是确保数据集质量和可靠性的关键步骤,尤其是在医疗保健等敏感领域。传统的验证方法通常依赖于预定义的规则和模式。然而,像 o1 这样的高级模型可以理解数据的上下文和推理,从而提供更灵活、更智能的验证方法。
在本教程中,我们将:
- 生成包含不一致内容的医疗数据合成数据集。
- 定义一个函数,接收一行数据并验证其准确性
- 运行验证过程并计算准确性指标。
- 分析并解释结果。
from openai import OpenAI
import json
from IPython.display import display, HTML
from sklearn.metrics import precision_score, recall_score, f1_score
from concurrent.futures import ThreadPoolExecutor, as_completed
import csv
import pandas as pd
client = OpenAI()
MODEL = 'o1-preview'我们将使用合成数据生成手册中描述的许多原则来创建我们的数据集的基础。
我们将提示模型为我们的用例生成一组医疗数据集。我们为模型提供了详细的说明,说明如何创建数据集、遵循什么格式以及如何填充不准确的数据。我们还提供了几行示例数据来启动模型。
数据集中的每一行将包含以下字段:
- 患者 ID:随机生成的患者 ID
- 出生日期:患者的出生日期
- 性别:男/女
- 病史:既往诊断
- 目前用药:患者正在服用的药物
- 过敏:已确认过敏
- 实验室结果(葡萄糖 mg/dL)
- 诊断:当前诊断
- 治疗计划:当前治疗计划
- 是否有效:当前行数据是否有效(真/假)
- 问题:如果该行数据无效,那么问题是什么
数据中可能存在的不准确性的一些示例包括:
- 开具患者过敏的药物
- 当前药物与病史不符
- 治疗方案与诊断不符
def generate_data():
messages = [
{
"role": "user",
"content": """
You are a helpful assistant designed to generate data. You will be given a format for the data to generate and some examples of the data.
When generating Patient IDs, use the format 'P' followed by a three-digit number (e.g., P006, P941, P319).
Intentionally make some mistakes in the data generation and document them in the appropriate columns ('Is Valid' and 'Issue') if the row of data is invalid.
The types of mistakes to include are:
- **Allergy Contradictions**: Prescribing a medication that the patient is allergic to (e.g., prescribing Penicillin to a patient allergic to Penicillin).
- **Medical History and Medication Mismatch**: A patient with a medical condition not receiving appropriate medication (e.g., a diabetic patient not prescribed any diabetes medication).
- **Lab Results and Diagnosis Mismatch**: Lab results that do not support the diagnosis (e.g., normal glucose levels but diagnosed with Diabetes Type 2).
- **Other Plausible Mistakes**: Any other realistic errors that could occur in medical records, such as incorrect gender entries, impossible dates of birth, or inconsistent treatment plans.
Ensure that when 'Is Valid' is 'False', the 'Issue' column clearly explains the problem.
Return 100 rows of data for the user. Your response should strictly be in the format of a valid CSV.
Generate Synthetic Medical Records Dataset with the following columns:
- Patient ID: A randomly generated patient id
- Date of Birth: Date of birth of the patient
- Gender: M/F
- Medical History: Past diagnoses
- Current Medications: Medication the patient is taking
- Allergies: Identified allergies
- Lab Results (Glucose mg/dL)
- Diagnoses: Current diagnosis
- Treatment Plan: Current treatment plan
- Is Valid: Whether or not the current row of data is valid (True/False)
- Issue: If the row of data is not valid, what the issue is
Patient ID,Date of Birth,Gender,Medical History,Current Medications,Allergies,Lab Results (Glucose mg/dL),Diagnoses,Treatment Plan,Is Valid,Issue
P001,1980-05-14,M,Hypertension,Lisinopril,None,110,Hypertension,Continue Lisinopril,True,
P002,1975-11-30,F,Diabetes Type 2,Metformin,Penicillin,90,Diabetes Type 2,Continue Metformin,True,
P003,1990-07-22,F,Asthma,Albuterol,Aspirin,85,Asthma,Prescribe Albuterol,True,
P004,2000-03-10,M,None,Amoxicillin,Penicillin,95,Infection,Prescribe Amoxicillin,False,Prescribed Amoxicillin despite Penicillin allergy
P005,1985-09-18,F,Hyperlipidemia,Atorvastatin,None,200,Hyperlipidemia,Continue Atorvastatin,True,
P006,1978-12-05,M,Hypertension; Diabetes Type 2,Lisinopril; Insulin,None,55,Diabetes Type 2,Adjust insulin dosage,False,Low glucose level not properly addressed
"""
}
]
response = client.chat.completions.create(
model=MODEL,
messages=messages
)
return response.choices[0].message.content.replace('```csv', '').replace('```', '')# Generate data three times using the existing dataGeneration function
generated_data = []
data = generate_data()
generated_data.extend(data.strip().split('\n'))
# Append the generated data to the medicalData.csv file
with open('../data/medicalData.csv', 'a', newline='') as csvfile:
csvwriter = csv.writer(csvfile)
for row in generated_data:
csvwriter.writerow(row.split(','))
print("Synthetic data generation and appending completed.")合成数据生成和附加已完成。
现在我们已经准备好了数据集,我们将提示推理模型检查每一行数据并确定它是否包含问题。我们将要求模型输出数据中是否存在问题,然后提供对问题的解释。
一旦模型确定了无效数据列表,我们就会将这些结果传递给模型分级器来评估两个指标:
- 模型正确识别数据问题的能力的准确性
- 对于已正确识别问题的数据子集,模型识别当前问题的准确率是多少
鉴于这个任务范围要窄得多,我们可以使用更快的 GPT-4O 模型来计算准确度。
提醒:鉴于这些模型仍处于测试阶段,速率限制将大幅降低。请相应调整并发工作者的数量。
def validate_data(input_data):
messages = [
{
"role": "user",
"content": f"""
You are a helpful assistant designed to validate the quality of medical datasets. You will be given a single row of medical data, and your task is to determine whether the data is valid.
- Carefully analyze the data for any inconsistencies, contradictions, missing values, or implausible information.
- Consider the logical relationships between different fields (e.g., treatments should be appropriate for the diagnoses, medications should not conflict with allergies, lab results should be consistent with diagnoses, etc.).
- Use your general medical knowledge to assess the validity of the data.
- Focus solely on the information provided without making assumptions beyond the given data.
**Return only a JSON object** with the following two properties:
- `"is_valid"`: a boolean (`true` or `false`) indicating whether the data is valid.
- `"issue"`: if `"is_valid"` is `false`, provide a brief explanation of the issue; if `"is_valid"` is `true`, set `"issue"` to `null`.
Both JSON properties must always be present.
Do not include any additional text or explanations outside the JSON object.
MEDICAL DATA:
{input_data}
"""
}
]
response = client.chat.completions.create(
model=MODEL,
messages=messages
)
response_content = response.choices[0].message.content.replace('```json', '').replace('```', '').strip()
try:
if isinstance(response_content, dict):
response_dict = response_content
else:
response_dict = json.loads(response_content)
return response_dict
except json.JSONDecodeError as e:
print(f"Failed to decode JSON response: {response_content}")# Read the CSV file and exclude the last two columns
input_data = []
with open('../data/medicalData.csv', 'r') as file:
reader = csv.reader(file)
headers = next(reader)
for row in reader:
input_data.append(row[:-2]) # Exclude "Is Valid" and "Issue" columns
# Initialize lists to store true labels
true_is_valid = []
true_issues = []
# Extract true labels from the CSV file
with open('../data/medicalData.csv', 'r') as file:
reader = csv.reader(file)
headers = next(reader)
for row in reader:
true_is_valid.append(row[-2] == 'True')
true_issues.append(row[-1])
# Function to validate a single row of data
def validate_row(row):
input_str = ','.join(row)
result_json = validate_data(input_str)
return result_json
# Validate data rows and collect results
pred_is_valid = [False] * len(input_data)
pred_issues = [''] * len(input_data)
with ThreadPoolExecutor() as executor:
futures = {executor.submit(validate_row, row): i for i, row in enumerate(input_data)}
for future in as_completed(futures):
i = futures[future] # Get the index of the current row
result_json = future.result()
pred_is_valid[i] = result_json['is_valid']
pred_issues[i] = result_json['issue']现在我们有了模型的结果,我们可以将其与事实来源进行比较,并确定系统的准确性
# Convert predicted and true 'is_valid' labels to boolean if they aren't already
pred_is_valid_bool = [bool(val) if isinstance(val, bool) else val == 'True' for val in pred_is_valid]
true_is_valid_bool = [bool(val) if isinstance(val, bool) else val == 'True' for val in true_is_valid]
# Calculate precision, recall, and f1 score for the 'is_valid' prediction
precision = precision_score(true_is_valid_bool, pred_is_valid_bool, pos_label=True)
recall = recall_score(true_is_valid_bool, pred_is_valid_bool, pos_label=True)
f1 = f1_score(true_is_valid_bool, pred_is_valid_bool, pos_label=True)
# Initialize issue_matches_full with False
issue_matches_full = [False] * len(true_is_valid)print(f"Precision: {precision:.2f}")
print(f"Recall: {recall:.2f}")
print(f"F1: {f1:.2f}")准确率:0.82召回率:0.87 F1:0.84
我们现在将确定模型准确对数据中的问题进行分类的能力
def validate_issue(model_generated_answer, correct_answer):
messages = [
{
"role": "user",
"content": f"""
You are a medical expert assistant designed to validate the quality of an LLM-generated answer.
The model was asked to review a medical dataset row to determine if the data is valid. If the data is not valid, it should provide a justification explaining why.
Your task:
• Compare the model-generated justification with the correct reason provided.
• Determine if they address the same underlying medical issue or concern, even if phrased differently.
• Focus on the intent, medical concepts, and implications rather than exact wording.
Instructions:
• If the justifications have the same intent or address the same medical issue, return True.
• If they address different issues or concerns, return False.
• Only respond with a single word: True or False.
Examples:
1. Example 1:
• Model Generated Response: “The patient is allergic to penicillin”
• Correct Response: “The patient was prescribed penicillin despite being allergic”
• Answer: True
2. Example 2:
• Model Generated Response: “The date of birth of the patient is incorrect”
• Correct Response: “The patient was prescribed penicillin despite being allergic”
• Answer: False
Model Generated Response: {model_generated_answer}
Correct Response: {correct_answer}
"""
}
]
response = client.chat.completions.create(
model="o1-preview",
messages=messages
)
result = response.choices[0].message.content
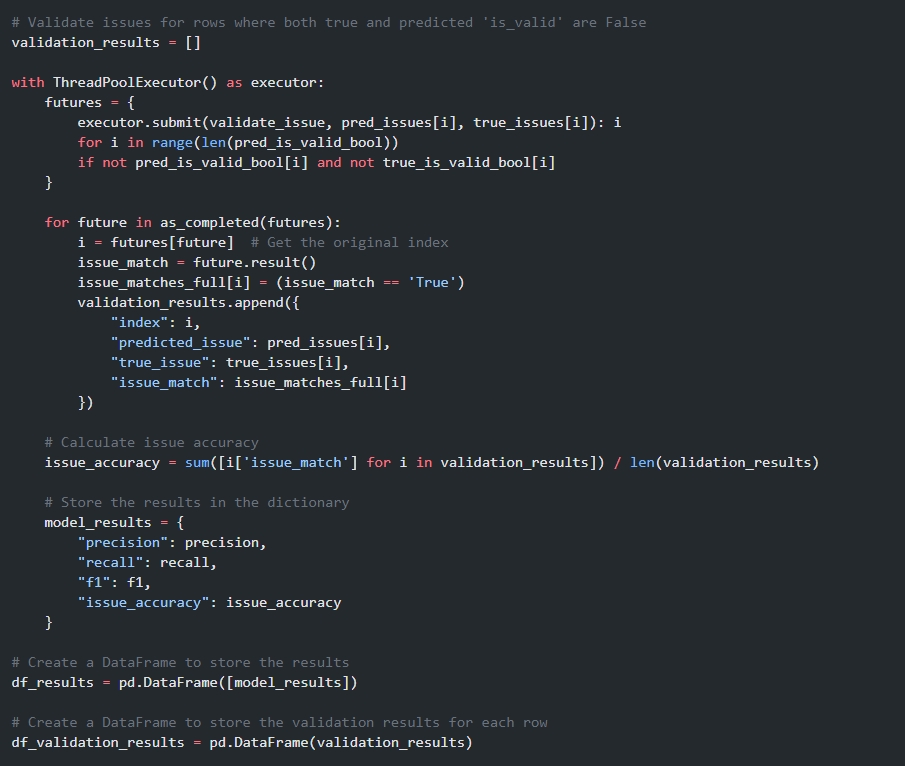
return result# Validate issues for rows where both true and predicted 'is_valid' are False
validation_results = []
with ThreadPoolExecutor() as executor:
futures = {
executor.submit(validate_issue, pred_issues[i], true_issues[i]): i
for i in range(len(pred_is_valid_bool))
if not pred_is_valid_bool[i] and not true_is_valid_bool[i]
}
for future in as_completed(futures):
i = futures[future] # Get the original index
issue_match = future.result()
issue_matches_full[i] = (issue_match == 'True')
validation_results.append({
"index": i,
"predicted_issue": pred_issues[i],
"true_issue": true_issues[i],
"issue_match": issue_matches_full[i]
})
# Calculate issue accuracy
issue_accuracy = sum([i['issue_match'] for i in validation_results]) / len(validation_results)
# Store the results in the dictionary
model_results = {
"precision": precision,
"recall": recall,
"f1": f1,
"issue_accuracy": issue_accuracy
}
# Create a DataFrame to store the results
df_results = pd.DataFrame([model_results])
# Create a DataFrame to store the validation results for each row
df_validation_results = pd.DataFrame(validation_results)下面我们将显示我们正确识别出包含问题的行子集。对于每一行,我们将显示预测问题与真实问题,以及是否存在匹配
def display_formatted_dataframe(df):
def format_text(text):
return text.replace('\n', '<br>')
df_formatted = df.copy()
df_formatted['predicted_issue'] = df_formatted['predicted_issue'].apply(format_text)
df_formatted['true_issue'] = df_formatted['true_issue'].apply(format_text)
display(HTML(df_formatted.to_html(escape=False, justify='left')))
display_formatted_dataframe(pd.DataFrame(validation_results))| 指数 | 预测问题 | true_issue | 问题匹配 | |
|---|---|---|---|---|
| 0 | 三十九 | 给对青霉素过敏的患者开阿莫西林处方。 | 尽管对青霉素过敏,医生仍开阿莫西林 | 真的 |
| 1 | 50 | 被诊断为 1 型糖尿病的患者未服用任何药物,并且治疗栏列出的是诊断而不是适当的治疗方法。 | 未接受胰岛素治疗的 1 型糖尿病患者 | 真的 |
| 2 | 51 | 实验室结果 300 表明血糖过高,但没有记录诊断或治疗。 | 血糖水平极高但未被诊断或治疗 | 真的 |
| 3 | 二十六 | 尽管患者对青霉素过敏,医生仍给其开青霉素。 | 尽管对青霉素过敏,仍开具青霉素处方 | 真的 |
| 4 | 31 | 患者年龄(88岁)与出生日期(1996-11-05)不一致。 | 骨质疏松症患者未接受治疗 | 错误的 |
| 5 | 24 | “治疗计划”字段不应为“抑郁症”;它应具体说明针对抑郁症规定的治疗方法。 | 抑郁症患者未接受治疗 | 真的 |
| 6 | 3 | 患者对青霉素过敏,但医生开了阿莫西林。 | 尽管对青霉素过敏,医生仍开阿莫西林 | 真的 |
| 7 | 二十八 | 治疗领域包含“哮喘”,这是一种诊断,而不是治疗。 | 哮喘患者未接受任何药物治疗 | 错误的 |
| 8 | 7 | 对于患有哮喘且实验室检查结果较低(100)的患者,仅通过改变生活方式进行治疗而不使用药物,这是不合适的。 | 哮喘患者未接受任何药物治疗 | 真的 |
| 9 | 16 | 患者的年龄(86岁)与出生日期(1955-10-10)不符。 | 未接受治疗的 COPD 患者 | 错误的 |
| 10 | 53 | 所提供的年龄(92)与出生日期(1983-08-19)不一致。 | 抑郁症患者未接受治疗 | 错误的 |
| 11 | 23 | 治疗领域错误地列出了“高脂血症”,而不是适合诊断的治疗方法。 | 高脂血症患者未开任何药物 | 真的 |
| 12 | 十三 | 患者对磺胺类药物过敏,但医生给患者开了磺胺甲恶唑,这是一种磺胺类药物。 | 尽管对磺胺类药物过敏,仍开具磺胺类药物处方 | 真的 |
| 十三 | 98 | 尽管患者对青霉素过敏,医生还是给患者开了青霉素。 | 尽管对青霉素过敏,仍开具青霉素处方 | 真的 |
| 14 | 9 | 患者对青霉素过敏,但医生开了青霉素。 | 尽管对青霉素过敏,仍开具青霉素处方 | 真的 |
| 15 | 85 | 治疗领域包含“高脂血症”,这是一种诊断,而不是治疗方法。 | 高脂血症患者未开任何药物 | 错误的 |
| 16 | 18 | 处方治疗(阿司匹林)不适合诊断感染。 | 尽管对阿司匹林过敏,仍开具阿司匹林处方;高血糖水平未得到解决 | 错误的 |
| 17 | 70 | 治疗领域包含诊断“骨质疏松症”而不是治疗方法。 | 骨质疏松症患者未接受治疗 | 真的 |
| 18 | 57 | 患者对青霉素过敏,但医生给其开了阿莫西林,但这是禁忌的。 | 尽管对青霉素过敏,医生仍开阿莫西林 | 真的 |
| 19 | 80 | 治疗领域错误地列出了“2 型糖尿病”,而不是有效的治疗计划。 | 未接受药物治疗的 2 型糖尿病患者 | 真的 |
| 20 | 87 | 治疗计划包括开具患者过敏的阿莫西林。 | 尽管对青霉素过敏,医生仍开阿莫西林 | 真的 |
| 21 | 三十七 | 治疗领域包含“高脂血症”,这是一种诊断,而不是治疗方法。 | 高脂血症患者未开任何药物 | 错误的 |
| 22 | 95 | 治疗方法被列为“哮喘”,但这并不是适合该诊断的治疗方法。 | 哮喘患者未接受任何药物治疗 | 真的 |
| 23 | 96 | 治疗领域列出了“高脂血症”,这不是合适的治疗方法。 | 高脂血症患者未开任何药物 | 错误的 |
| 24 | 59 | 治疗领域包含“贫血”,这不是有效的治疗方法。 | 贫血患者未接受治疗 | 错误的 |
| 二十五 | 5 | 年龄与出生日期不符 | 低血糖水平未得到适当解决 | 错误的 |
# Display the DataFrame
print(df_results)准确率 召回率 f1 问题准确率 0 0.818182 0.870968 0.84375 0.615385
结论
从结果中我们可以看出,我们能够生成高精度/高精度的问题识别率,以及高精度的数据查明率。
这有助于简化跨各种领域的评估集的数据验证。