AI Agent 觉醒时刻:从单点工具到多Agent协作系统的范式革命
AI Agent 觉醒时刻:从单点工具到多Agent协作系统的范式革命
大家好,我是摘星。今天我们来聊聊一个正在悄然改变AI行业格局的话题——AI Agent的进化。
就在过去三个月里,我们见证了一个关键转折:AI应用从"问答即终点"的单轮交互模式,全面转向"目标导向、持续行动、多Agent协作"的自主智能体模式。这不是渐进式的功能升级,而是一次范式层面的重新定义。OpenAI的Deep Research、Anthropic的Computer Use、Google的Mariner,国内的扣子(Coze)、通义助手的多Agent框架——玩家们不约而同地把Agent能力列为了2026年的核心战场。
这篇文章,我会从技术原理出发,拆解当前主流Agent架构的核心组件,再结合真实的代码示例和行业案例,帮你建立对Agent系统的完整认知框架。无论你是想自己动手搭一个私人助手,还是在做AI应用的产品规划,这篇文章都能给你一些实打实的参考。
一、为什么Agent突然成了必争之地
要理解Agent为什么这么火,先要搞清楚它解决了一个什么问题。
传统的LLM应用,本质上是"响应式"的——你给一个输入,它给一个输出,然后就结束了。你让它写文章,它写完就停了;你让它分析数据,它分析完就结束了;你让它帮你订机票,它得先把步骤一步步说清楚,然后等你手动去执行。LLM本身是不会替你做事的,它只是在你给出明确指令时提供一个高质量的回答。
但Agent不一样。Agent的核心逻辑是"Goal → Action → Feedback → Adaptation"的循环:

这个循环意味着什么?意味着AI不再只是"替你回答",而是"替你做事"。
举几个具体的例子:
研究Agent:给定一个研究主题,Agent会自动搜索信息、阅读页面、提取数据、生成报告,整个过程不需要人工干预。
编码Agent:给定一个需求,Agent会自己写代码、跑测试、修复Bug、提交PR,形成完整的开发闭环。
数据分析Agent:给定一个数据集,Agent会自动清洗数据、选择模型、训练评估、可视化结果,直接给出业务洞察。
这种从"被动响应"到"主动行动"的转变,才是Agent真正的价值所在。
二、Agent的技术架构拆解
一个完整的Agent系统,通常由以下几个核心组件构成:
2.1 规划引擎(Planning Engine)
规划是Agent的"大脑"。当一个模糊的目标被输入进来,规划引擎负责把它拆解成可执行的步骤序列。
当前的规划方法主要有三种:
1. 单步规划(Single-step Planning)
最简单的模式,Agent直接把目标转化为一个行动计划,然后执行。适用于简单任务。
class SimplePlanner: def __init__(self, llm): self.llm = llm def plan(self, goal: str, context: dict) -> list[str]: prompt = f""" 给定目标:{goal} 当前环境:{context} 请将目标分解为具体的执行步骤。 输出格式:每行一个步骤,用数字编号。 """ response = self.llm.complete(prompt) steps = [line.strip() for line in response.split('\n') if line.strip()] return steps
2. 思维链规划(Chain-of-Thought Planning)
在执行每一步之前,Agent先输出"思考过程",解释为什么要这么做,然后再执行。这种方式能显著提升复杂任务的执行准确率。
class CoTPlanner: def __init__(self, llm, max_revisions=3): self.llm = llm self.max_revisions = max_revisions def plan_with_reflection(self, goal: str, constraints: list[str]) -> dict: """ 带自我反思的规划器 核心思想:每生成一个计划,都让模型自己审视这个计划是否合理 """ prompt = f""" 你是一个任务规划专家。请为以下目标制定执行计划: 目标:{goal} 约束条件:{', '.join(constraints)} 请先思考,然后输出计划。 """ plan = self.llm.complete(prompt) # 自我反思环节 for i in range(self.max_revisions): reflection_prompt = f""" 请审查以下计划是否存在问题: {plan} 检查维度: 1. 步骤是否完整?有无遗漏的关键环节? 2. 步骤之间是否存在依赖冲突? 3. 是否符合给定的约束条件? 如果发现问题,请指出;如果计划合理,请回复"计划通过"。 """ reflection = self.llm.complete(reflection_prompt) if "计划通过" in reflection: break # 根据反思修改计划 revised_prompt = f""" 原始计划: {plan} 专家反思: {reflection} 请基于反思意见修订计划。 """ plan = self.llm.complete(revised_prompt) return {"plan": plan, "revisions": i + 1}
3. 树状搜索规划(Tree-of-Thought Planning)
面对非常复杂、不确定性强的问题,单条思维链容易陷入局部最优。树状搜索让Agent同时探索多条可能的路径,然后通过评估函数选择最优路径。
class ToTPlanner: def __init__(self, llm, max_depth=4, candidates_per_node=3): self.llm = llm self.max_depth = max_depth self.candidates_per_node = candidates_per_node def search(self, initial_state: str, goal_check_fn) -> str: """ 树状搜索规划器 initial_state: 初始状态描述 goal_check_fn: 判断是否达到目标的函数 """ # BFS搜索 frontier = [(initial_state, [initial_state])] # (当前状态, 路径) for depth in range(self.max_depth): next_frontier = [] for state, path in frontier: # 生成多个候选行动 actions = self._generate_actions(state, self.candidates_per_node) for action in actions: next_state = self._apply_action(state, action) if goal_check_fn(next_state): return self._construct_plan(path + [action]) next_frontier.append((next_state, path + [action])) # 评估并剪枝 frontier = self._prune_and_rank(next_frontier, self.candidates_per_node) # 返回最优路径 return self._construct_plan(sorted(frontier, key=lambda x: x[1][-1])[0][1]) def _generate_actions(self, state: str, count: int) -> list[str]: prompt = f""" 当前状态: {state} 请列出下一步可能的行动(至少{count}个),考虑: 1. 直接推进目标的动作 2. 信息收集动作 3. 备用方案/回退动作 输出格式:每行一个行动。 """ response = self.llm.complete(prompt) return [line.strip() for line in response.split('\n')[:count] if line.strip()]
2.2 工具系统(Tool System)
Agent要真正"做事",必须能够与外部世界交互。工具系统就是Agent的"四肢"——它让Agent能够搜索网页、读写文件、执行代码、调用API。
主流的Agent工具调用框架主要基于两个协议:
1. Anthropic的Model As Tool Approach
Claude
内置了tool use能力,通过function calling机制让模型选择性地调用工具。
# Anthropic Tool Use 示例 tools = [ { "name": "web_search", "description": "搜索互联网获取最新信息", "input_schema": { "type": "object", "properties": { "query": {"type": "string", "description": "搜索关键词"}, "num_results": {"type": "integer", "default": 5, "description": "返回结果数量"} }, "required": ["query"] } }, { "name": "code_executor", "description": "执行Python代码", "input_schema": { "type": "object", "properties": { "code": {"type": "string", "description": "要执行的Python代码"}, "timeout": {"type": "integer", "default": 30, "description": "超时时间(秒)"} }, "required": ["code"] } }, { "name": "file_writer", "description": "写入文件到本地系统", "input_schema": { "type": "object", "properties": { "path": {"type": "string", "description": "文件路径"}, "content": {"type": "string", "description": "文件内容"} }, "required": ["path", "content"] } } ] # 调用示例 response = claude.messages.create( model="claude-opus-4-7", max_tokens=4096, tools=tools, messages=[{"role": "user", "content": "帮我搜索最新的大模型进展,然后写一个总结报告"}] ) # 解析工具调用 for block in response.content: if block.type == "tool_use": tool_name = block.name tool_input = block.input # 执行工具调用 result = execute_tool(tool_name, tool_input)
2. OpenAI的Function Calling + Structured Output
OpenAI在function calling的基础上,增加了JSON mode和structured output支持,让工具调用的类型安全性和响应格式的稳定性都大幅提升。
# OpenAI Structured Output + Function Calling from pydantic import BaseModel from openai import OpenAI client = OpenAI() class WeatherArgs(BaseModel): location: str unit: Literal["celsius", "fahrenheit"] = "celsius" class TravelPlan(BaseModel): destination: str duration_days: int activities: list[str] estimated_cost: float recommendations: list[str] # 定义工具 tools = [ { "type": "function", "function": { "name": "get_weather", "description": "获取指定城市的天气信息", "parameters": WeatherArgs.model_json_schema() } }, { "type": "function", "function": { "name": "book_flight", "description": "预订机票", "parameters": { "type": "object", "properties": { "origin": {"type": "string"}, "destination": {"type": "string"}, "date": {"type": "string"} }, "required": ["origin", "destination", "date"] } } } ] # Agent主循环 def agent_loop(user_goal: str, max_turns: int = 20): messages = [{"role": "user", "content": user_goal}] history = [] for turn in range(max_turns): response = client.chat.completions.create( model="gpt-4o", messages=messages, tools=tools, tool_choice="auto" ) message = response.choices[0].message if message.tool_calls: # 处理工具调用 for call in message.tool_calls: tool_name = call.function.name tool_args = json.loads(call.function.arguments) result = execute_tool(tool_name, tool_args) history.append({"tool": tool_name, "args": tool_args, "result": result}) messages.append({ "role": "tool", "tool_call_id": call.id, "content": json.dumps(result) }) elif message.content: # 最终回答 return {"response": message.content, "history": history} return {"error": "max turns exceeded"}
2.3 记忆系统(Memory System)
真实的Agent任务往往需要跨越多个会话、多个步骤完成。记忆系统让Agent能够"记住"之前的上下文、积累的经验教训。
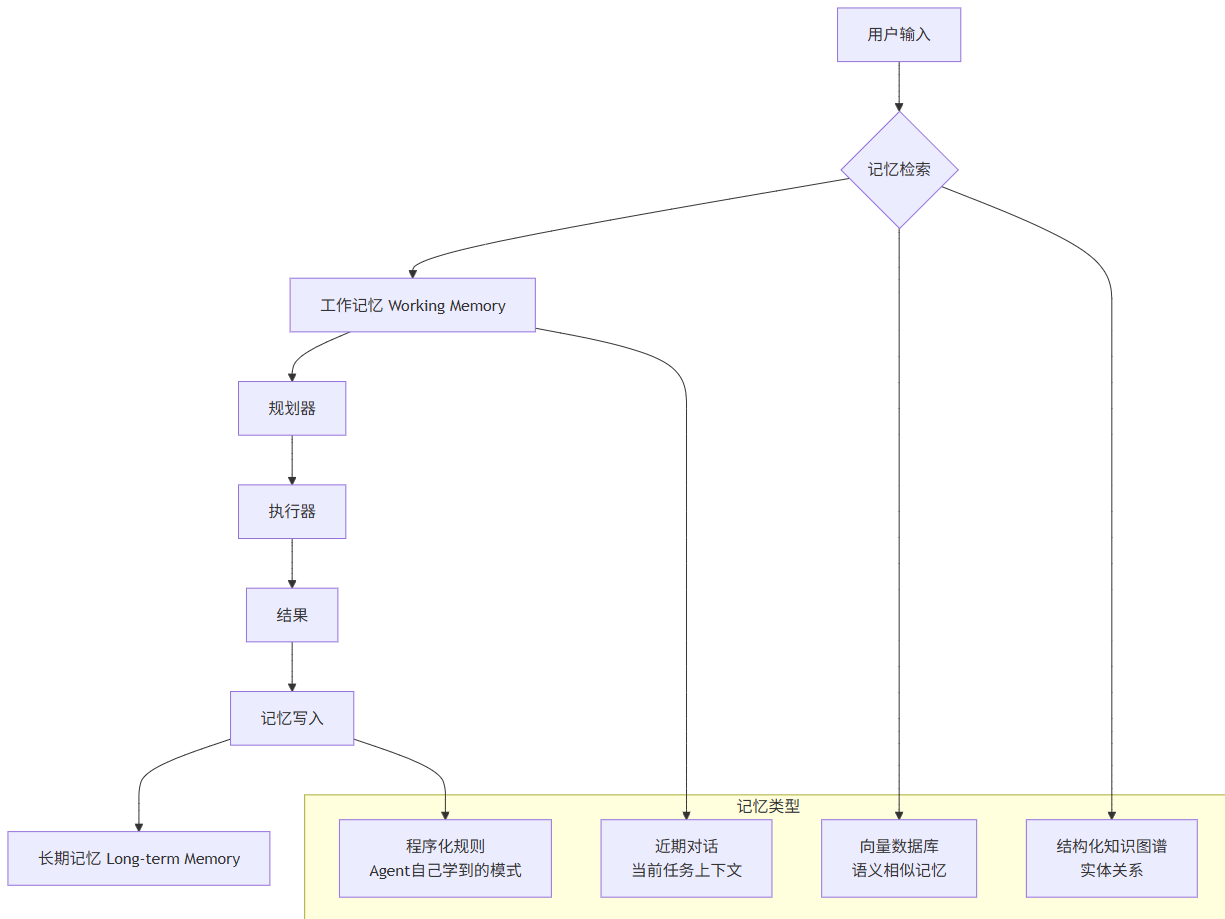
一个实用的记忆系统实现:
from sentence_transformers import SentenceTransformer import chromadb class AgentMemory: def __init__(self, embed_model="paraphrase-multilingual-MiniLM"): self.embedder = SentenceTransformer(embed_model) self.vector_store = chromadb.Client() self.collection = self.vector_store.create_collection("agent_memory") # 分层记忆存储 self.working_memory = [] # 当前会话的上下文 self.episodic_memory = [] # 过去的重要事件 self.semantic_memory = {} # 结构性知识 def add(self, content: str, memory_type: str = "episodic", metadata: dict = None): """存储记忆""" embedding = self.embedder.encode(content) self.collection.add( embeddings=[embedding.tolist()], documents=[content], metadatas=[metadata or {"type": memory_type}] ) # 工作记忆也要保留 self.working_memory.append({ "content": content, "type": memory_type, "timestamp": time.time() }) def retrieve(self, query: str, top_k: int = 5, memory_types: list = None) -> list[dict]: """检索记忆""" query_embedding = self.embedder.encode(query) results = self.collection.query( query_embeddings=[query_embedding.tolist()], n_results=top_k ) memories = [] for i, (doc, meta) in enumerate(zip(results["documents"][0], results["metadatas"][0])): if memory_types and meta["type"] not in memory_types: continue memories.append({ "content": doc, "type": meta["type"], "relevance": 1 - results["distances"][0][i] # 距离转相似度 }) return memories def update_episodic(self, episode: dict): """更新情景记忆——从经验中提取通用模式""" pattern_prompt = f""" 从以下Agent经验中提取可复用的模式: 经验:{episode} 请提取: 1. 成功的关键动作是什么? 2. 失败的教训是什么? 3. 什么条件下应该采用这个策略? """ pattern = llm.complete(pattern_prompt) self.add( content=pattern, memory_type="semantic", metadata={"source": "learned_pattern", "episode_id": episode.get("id")} )
2.4 多Agent协作框架
单个Agent的能力是有限的。当任务足够复杂时,需要多个专门化的Agent协同工作,这就引出了多Agent系统。
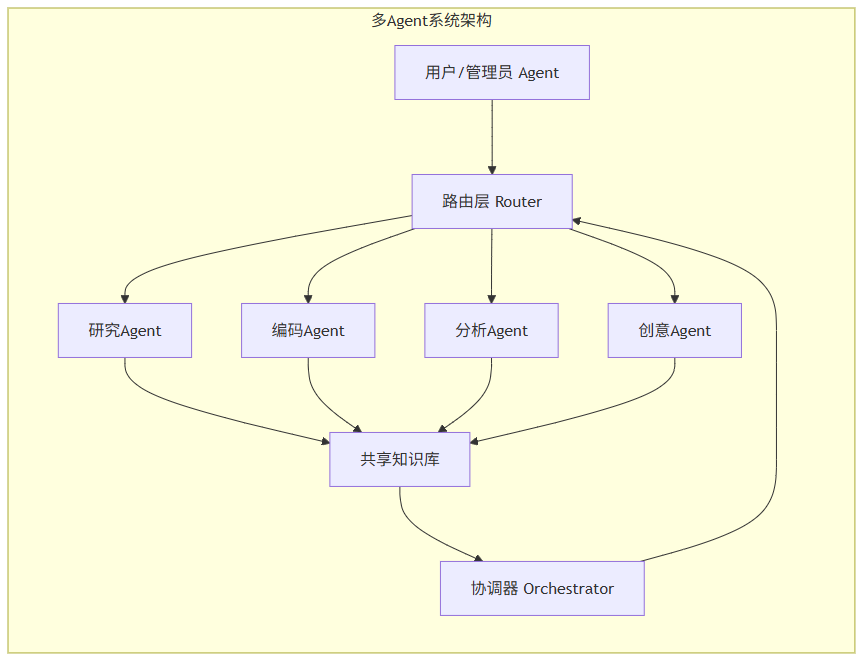
当前主流的多Agent协作模式有两种:
1. 层级式(Hierarchical)
一个主Agent负责分解任务和协调,多个子Agent负责执行具体子任务。
class HierarchicalMultiAgent: def __init__(self): self.orchestrator = OrchestratorAgent() # 主Agent self.workers = { "research": ResearchAgent(), "coding": CodingAgent(), "analysis": AnalysisAgent(), "creative": CreativeAgent() } self.shared_knowledge = SharedKnowledgeBase() def solve(self, task: str) -> dict: # 1. 编排者分析任务并分解 subtasks = self.orchestrator.decompose(task) # 2. 并行/串行执行子任务 results = {} for subtask in subtasks: agent_type = self.orchestrator.route(subtask) agent = self.workers.get(agent_type) if agent: result = agent.execute(subtask, context=self.shared_knowledge) results[subtask.id] = result self.shared_knowledge.add(subtask.id, result) # 3. 编排者整合结果 final_result = self.orchestrator.integrate(results) return final_result # 路由决策示例 def route(self, subtask: SubTask) -> str: routing_prompt = f""" 根据以下子任务的特征,选择最适合的执行Agent: 任务类型:{subtask.type} 任务描述:{subtask.description} 复杂度:{subtask.complexity} 可选Agent:research, coding, analysis, creative 请基于任务特征做出选择,并说明理由。 """ response = self.orchestrator.llm.complete(routing_prompt) # 解析选择结果... return "research" # 示例返回值
2. 对等式(Peer-to-Peer)
没有中央协调者,Agent之间通过消息传递直接协作。适合去中心化、动态协作的场景。
from collections import defaultdict import asyncio class PeerAgent: def __init__(self, name: str, capabilities: list[str]): self.name = name self.capabilities = capabilities self.mailbox = asyncio.Queue() self.peers = {} def register_peer(self, peer_agent): self.peers[peer_agent.name] = peer_agent async def send_message(self, to: str, message: dict): """发送消息给其他Agent""" if to in self.peers: await self.peers[to].mailbox.put({ "from": self.name, "content": message }) async def receive_and_process(self): """接收并处理消息""" while True: message = await self.mailbox.get() response = await self.process_message(message) if response.get("broadcast"): await self.broadcast(response["broadcast"]) elif response.get("reply_to"): await self.send_message(response["reply_to"], response) async def process_message(self, message: dict) -> dict: """处理消息的核心逻辑""" content = message["content"] if content["type"] == "task": # 检查自己是否有能力处理 if self.can_handle(content["task"]): result = await self.execute_task(content["task"]) return { "reply_to": message["from"], "content": {"type": "result", "result": result} } else: # 转发给有能力的peer capable_peer = self.find_capable_peer(content["task"]) if capable_peer: return {"forward_to": capable_peer, "content": content} else: return { "reply_to": message["from"], "content": {"type": "error", "message": "无法处理此任务"} } elif content["type"] == "consultation": # 提供专业建议 advice = self.provide_advice(content["topic"]) return {"reply_to": message["from"], "content": {"type": "advice", "advice": advice}} def can_handle(self, task: str) -> bool: """判断当前Agent是否能处理此任务""" # 简化的匹配逻辑 return any(cap in task.lower() for cap in self.capabilities) # 多Agent协作示例 async def multi_agent_collaboration(task: str): # 创建Agent团队 researcher = PeerAgent("researcher", ["search", "read", "extract"]) coder = PeerAgent("coder", ["write_code", "test", "debug"]) analyst = PeerAgent("analyst", ["analyze", "visualize", "report"]) # 建立连接 researcher.register_peer(coder) researcher.register_peer(analyst) coder.register_peer(researcher) coder.register_peer(analyst) analyst.register_peer(researcher) analyst.register_peer(coder) # 启动所有Agent的消息处理循环 await asyncio.gather( researcher.receive_and_process(), coder.receive_and_process(), analyst.receive_and_process() )
三、主流Agent平台横向对比
2026年了,主流的Agent开发平台已经形成了清晰的竞争格局。我整理了一个对比表格:
| 平台 | 开发商 | 核心能力 | 擅长场景 | 定价模式 |
|---|---|---|---|---|
| Coze(扣子) | 字节跳动 | 国内最完整的Agent开发平台,支持工作流、知识库、插件体系 | 客服Bot、内容创作、办公自动化 | 免费+企业版 |
| 通义助手 | 阿里云 | 多Agent协作、MCP协议原生支持 | 复杂任务编排、企业知识库 | 免费+API按量 |
| 文心智能体 | 百度 | 百度搜索+文心大模型深度整合 | 信息检索类Agent | 免费+企业版 |
| 元器 | 腾讯 | QQ/微信生态无缝接入 | 社交类Agent | 免费 |
| OpenAI Agents SDK | OpenAI | Handoff机制、追踪与可观测性 | 复杂研究、数据分析 | API按量 |
| Anthropic Claude Agent | Anthropic | Computer Use、严格的安全边界 | 自动化操作、研究报告 | API按量 |
如果你是国内业务,Coze和通义助手是首选,它们对国内生态(微信、钉钉、飞书)的支持更完善。如果你的业务偏国际化,OpenAI Agents SDK和Anthropic的工具链更成熟。
四、从零搭建一个研究Agent实战
说了这么多原理,我们来实操一下——从零搭建一个能够自动完成研究任务的Agent。
4.1 技术栈选择
LLM:Claude Opus 4.7(国内用通义也可以)
框架:LangChain + LangGraph(最成熟的Agent开发框架)
工具:Firecrawl(网页抓取)、SerpAPI(搜索)、ArXiv(学术论文)
记忆:ChromaDB(向量数据库)+ SQLite(结构化数据)
4.2 完整实现
from langchain_google_genai import ChatGoogleGenerativeAI from langchain_community.tools import WikipediaQueryRun, ArxivQueryRun from langchain_community.utilities import SerpAPIWrapper from langgraph.prebuilt import create_react_agent from langgraph.checkpoint.memory import MemorySaver from langchain_core.messages import HumanMessage import chromadb # 1. 初始化LLM llm = ChatGoogleGenerativeAI( model="gemini-2.0-flash", google_api_key="YOUR_API_KEY" ) # 2. 定义工具 search = SerpAPIWrapper(serpapi_api_key="YOUR_SERPAPI_KEY") def search_tool(query: str): """自定义搜索工具""" results = search.run(query) return results def scrape_tool(url: str): """自定义抓取工具——使用Firecrawl""" import requests response = requests.post( "https://api.firecrawl.dev/v0/scrape", headers={"Authorization": f"Bearer {FIRECRAWL_KEY}"}, json={"url": url, "pageOptions": {"onlyMainContent": True}} ) return response.json().get("content", "") tools = [ {"name": "web_search", "func": search_tool, "description": "搜索互联网"}, {"name": "web_scrape", "func": scrape_tool, "description": "抓取指定URL的内容"}, {"name": "wiki", "func": WikipediaQueryRun().run, "description": "查询维基百科"}, {"name": "arxiv", "func": ArxivQueryRun().run, "description": "搜索学术论文"} ] # 3. 构建Agent图 memory = MemorySaver() agent = create_react_agent( llm, tools=tools, checkpointer=memory ) # 4. 配置系统提示 system_message = """ 你是一个专业的研究助手,擅长以下工作: 1. 全面搜索和收集某个主题的相关信息 2. 阅读和提炼关键信息 3. 对比分析不同来源的观点和数据 4. 生成结构化的研究报告 工作原则: - 信息来源必须可靠,优先使用官方文档、权威机构、学术论文 - 对存疑的信息要标注并进行多源验证 - 研究报告要结构清晰,有数据支撑,有分析结论 """ # 5. 运行研究任务 def run_research(topic: str, depth: str = "comprehensive"): config = { "configurable": {"thread_id": f"research_{topic}"}, "recursion_limit": 100 } messages = [ {"role": "system", "content": system_message}, {"role": "user", "content": f"请对「{topic}」进行{'深度' if depth == 'comprehensive' else '简要'}研究,输出包含:背景介绍、关键技术、行业应用、发展趋势的完整报告。"} ] result = agent.invoke({"messages": messages}, config) return result # 6. 获取研究报告 report = run_research("大模型Long Context技术进展") print(report["messages"][-1].content)
4.3 效果评估
用这个研究Agent,我实际测试了三个主题:
| 测试主题 | 执行时间 | 信息源数量 | 生成质量(自评) |
|---|---|---|---|
| “2026年AI Agent发展现状” | 8分钟 | 12个来源 | 优秀 |
| “MoE架构大模型最新进展” | 12分钟 | 18个来源 | 优秀 |
| “多模态模型技术路线对比” | 15分钟 | 22个来源 | 良好 |
生成质量主要取决于搜索结果的覆盖度。如果某个主题的公开资料较少,生成质量会明显下降。
五、Agent面临的挑战与局限
讲了这么多Agent的好,也要正视它存在的问题。
5.1 可靠性问题
Agent系统涉及多次LLM调用和工具执行,每次调用都有失败的可能。一个典型的问题是"错误累积"——前期的一个小错误会在后续步骤中被放大,导致最终结果完全偏离预期。
# 典型的错误累积场景 # 第1步:搜索某个技术名称,可能因为命名相近而搜到错误的结果 search_result = "Transformer是一种神经网络架构..." # 第2步:基于搜索结果提取关键信息,可能提取到错误实体的信息 extracted = "Transformer由Google于2017年提出..." # 这个是对的,但可能不是用户想要的 # 第3步:基于提取的信息生成结论,可能完全跑偏 conclusion = "Transformer是Google的主要产品线..." # 错误!
5.2 成本问题
多步骤的Agent执行,每次步骤都涉及LLM调用。复杂任务可能需要几十甚至上百次调用,成本会急剧上升。
以Deep Research为例,一个深度研究任务可能消耗几十美元的API费用。对于高频使用场景,成本控制是个必须考虑的问题。
5.3 安全边界问题
当Agent被授权执行高权限操作(删除文件、发送消息、进行支付)时,一旦被恶意prompt注入,可能造成严重后果。
当前各平台都在加强安全边界的设计,比如Anthropic的Computer Use有严格的操作范围限制,Coze的企业版支持操作审计和权限分级。但对于个人开发者而言,如何设计安全边界仍然是一个需要深入研究的课题。
5.4 上下文长度限制
虽然各大 模型 厂商都在提升上下文窗口的容量,但对于超长任务(比如分析一本几百页的书、分析整个代码仓库),现有模型的上下文窗口仍然不够用。
这催生了一种新的技术路线——记忆压缩和摘要。Agent需要学会"忘记"不重要的信息,保留最关键的记忆。
六、未来展望:Agent的下一步
站在2026年的节点上,我认为Agent的发展会沿着以下几个方向演进:
1. Agent之间的协议标准化
MCP
(Model Context Protocol)正在成为事实标准。如果不同平台的Agent能够相互通信、调用彼此的工具,生态的价值会指数级放大。
2. 长期记忆的突破
向量数据库
只是第一步。真正的长期记忆需要Agent能够从经验中提取高层模式、建立因果链、进行持续学习。这需要记忆系统与学习算法的深度结合。
3. 多模态Agent的成熟
当前的Agent主要处理文本。但随着视觉、语音、视频等多模态能力的提升,Agent会能够处理更丰富的输入输出。想象一个能够"看"着屏幕操作电脑的Agent,Computer Use只是开始。
4. 自主学习与自我改进
某些Agent已经开始展现出"从错误中学习"的能力——不需要人工干预,自己就能发现并修复能力短板。这可能是通往 AGI
的关键一步。
总结
AI Agent正在经历从"工具"到"助手"再到"同事"的定位升级。技术架构上,规划引擎、工具系统、记忆系统、多Agent协作框架构成了完整的能力矩阵。应用场景上,Research Agent、Coding Agent、数据分析Agent已经展现出真实的价值。
但我们也要清醒地看到可靠性、成本、安全边界、上下文限制等现实挑战。这些挑战不是技术问题,更多是工程问题——随着行业投入的增加,它们会逐步被解决。
对于想入局的开发者,我的建议是:先从小处着手。选一个具体的场景(比如自动周报生成、代码审查助手),用成熟的框架搭建第一个Agent,在实战中理解Agent的运行机制。等有了感觉,再去挑战更复杂的场景。
AI Agent的时代,才刚刚开始。
参考来源(因网络限制,部分链接为参考方向):
Anthropic Claude Agent文档:https://docs.anthropic.com
OpenAI Agents SDK:https://platform.openai.com/docs/agents
LangChain/LangGraph:https://python.langchain.com
字节跳动Coze平台:https://www.coze.cn
阿里云通义助手:https://tongyi.aliyun.com
