【第1篇】Spring AI Alibaba 示例项目 - 最佳学习路线(从易到难)
项目概况
开源项目镜像地址:https://gitcode.com/gh_mirrors/sp/examples/tree/main
它是一个完整的 Spring AI Alibaba 示例集合,涵盖了从基础对话到高级 AI 应用开发的 30+ 个功能模块,支持阿里云通义千问、 OpenAI
、Azure、DeepSeek、ZhiPu、Moonshot 、本地模型等多个模型。
核心价值:这是 Java 开发者进入 AI 应用开发的最短路径——基于熟悉的 Spring 生态,无需学习 Python 或前端技术,就能构建生产级的 AI 应用。
️ 学习路线图
第一阶段:Hello World 入门
目标:搭建环境,理解基本概念,建立信心
这是你的第一个 AI 应用。就像学习任何新框架时先写 “Hello World” 一样,这个阶段让你快速验证环境是否就绪,并理解 Spring AI Alibaba 最基础的调用方式。

核心概念解析:
ChatClient:面向开发者的友好 API,封装了与 AI 模型的交互细节。你可以把它想象成一个"翻译官"——你说人话,它帮你转成模型能懂的格式,再把模型的回复转成人话。
ChatModel:底层模型接口,更灵活但需要你手动处理提示词模板。
Advisor(对话记忆):Spring AI 的"记忆插件",让 AI 记得你们之前的对话内容,实现多轮对话。
模块:spring-ai-alibaba-helloworld
| 学习重点 | 预计时间 |
|---|---|
| 环境准备(Java 17+、Maven、DashScope API Key) | 30分钟 |
| ChatClient 基础调用 | 1小时 |
| 流式响应(SSE) | 1小时 |
| 对话记忆(Advisor) | 2小时 |
| REST API 集成 | 2小时 |
代码示例:
@GetMapping("/simple/chat") public String simpleChat() { return chatClient.prompt() .user("你好,介绍一下你自己") .call() .content(); }
动手实操步骤:
访问 阿里云百炼平台 申请免费 API Key
设置环境变量:export AI_DASHSCOPE_API_KEY=your_key_here
克隆项目:git clone https://github.com/alibaba/spring-ai-alibaba-examples.git
进入 helloworld 目录,执行 mvn spring-boot:run
访问 http://localhost:8080/simple/chat 测试
避坑指南:
确保 Java 版本 ≥ 17(Spring AI Alibaba 的硬性要求)
如果 API 调用失败,先检查环境变量是否正确设置
流式响应需要前端支持 SSE(Server-Sent Events),测试时可以用 curl 观察效果
如果不想用阿里模型,也可以使用自己想用的,第2篇中会做一下些许的微调实现。
第二阶段:多模型对话
目标:掌握多模型切换和参数配置,理解不同模型的特点
当你能调用通义千问后,自然会想:能不能换成 GPT-4?能不能用 DeepSeek?这个阶段让你掌握"一个代码库,多模型切换"的能力。
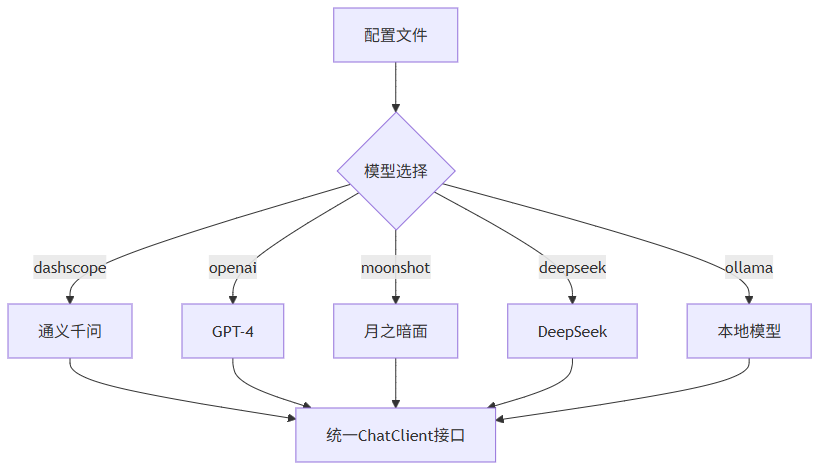
核心概念解析:
Temperature(温度):控制 AI 的"创造力"。0.1 是严谨的书呆子(适合代码生成),1.0 是脑洞大开的艺术家(适合创意写作)。
MaxTokens(最大令牌):控制回复长度。一个 token 约等于 0.75 个汉字,2000 tokens 大概能输出 1500 字。
多模态:让 AI 能"看懂"图片,实现图文对话。
模块:spring-ai-alibaba-chat-example
配置示例:
spring: ai: dashscope: api-key: ${AI_DASHSCOPE_API_KEY} chat: model: qwen-plus # 可选: qwen-turbo, qwen-max, qwen-coder options: temperature: 0.7 # 0-1之间,越小越确定,越大越创意 max-tokens: 2000 # 控制回复长度
支持的模型平台:
| 平台 | 特点 | 适用场景 |
|---|---|---|
| DashScope | 阿里云出品,国内访问快 | 国内业务首选 |
| OpenAI | 能力最强,价格较高 | 复杂推理任务 |
| Azure OpenAI | 企业级合规 | 外企/合规要求高的场景 |
| DeepSeek | 开源,性价比高 | 代码生成、数学推理 |
| Moonshot | 长文本能力强 | 文档分析、总结 |
| ZhiPu | 中文理解好 | 中文对话场景 |
| Ollama | 本地部署 | 数据隐私要求高 |
动手实操:
在配置文件中切换不同模型,观察同一问题的回答差异
调整 temperature 参数(0.1 vs 0.9),感受"严谨"与"创意"的区别
尝试图片分析功能:上传一张图片,让 AI 描述内容
第三阶段:工具调用(Tool Calling)
目标:让 AI 调用外部工具,实现真实业务场景
这是 AI 从"聊天机器人"进化到"智能助手"的关键一步。通过工具调用,AI 可以查天气、调 API、操作数据库,真正帮你干活。
核心概念解析:
@Tool 注解:把 Java 方法"注册"给 AI,AI 需要时自动调用。就像给 AI 一本"工具说明书"。
Function Calling 模式:AI 决定"要不要调用工具"以及"传什么参数",你的代码负责执行。
四种调用模式对比:
| 模式 | 适用场景 | 复杂度 |
|---|---|---|
| 方法作为工具 | 简单的本地方法调用 | ⭐ |
| MethodToolCallback | 需要复杂初始化的工具 | ⭐⭐ |
| Function Name 方式 | 调用第三方 REST API | ⭐⭐ |
| FunctionCallback 方式 | 需要自定义逻辑的复杂场景 | ⭐⭐⭐ |
代码示例:
@Service public class WeatherService { @Tool(name = "getWeather", description = "获取指定城市的天气信息") public String getWeather( @ToolParam(description = "城市名称,如重庆、北京") String city, @ToolParam(description = "温度单位,可选celsius/fahrenheit") String unit ) { // 实际调用天气 API return weatherApiClient.query(city); } } // 在 ChatClient 中注册工具 chatClient.prompt() .user("重庆今天天气怎么样?") .tools(weatherService) // 注册工具 .call() .content();
动手实操:
实现天气查询工具:调用和风天气或 OpenWeather API
实现计算器工具:让 AI 能进行精确数学计算(弥补 LLM 数学不好的短板)
实现数据库查询工具:让 AI 能查询你的业务数据(注意做好权限控制)
避坑指南:
工具描述(description)要写清楚,这决定了 AI 会不会正确调用
参数校验要做好,AI 可能会传奇怪的值
超时处理:外部 API 可能很慢,要设置合理的超时时间
第四阶段:RAG(检索增强生成)
目标:构建知识库问答系统,让 AI 基于你的私有数据回答
RAG 是"让 AI 懂你的业务"的核心技术。它把大模型的"通识能力"和你的"私有知识"结合,实现客服问答、文档分析、知识管理等场景。

核心概念解析:
Embedding(嵌入):把文字转成数学向量。语义相近的文字,在向量空间中也相近。这是"语义搜索"的基础。
Chunking(切片):长文档要切成小段,否则向量会"稀释"语义。就像一本书,按章节建立索引比整本书一个索引更精确。
向量数据库:专门存储和检索向量的数据库,支持"找相似"的数学运算。
子模块概览:
| 子模块 | 功能 | 难度 | 适用场景 |
|---|---|---|---|
| rag-pgvector-example | PostgreSQL + pgvector | ⭐⭐ | 已有 PG 基础设施的团队 |
| rag-elasticsearch-example | ES 向量检索(可以参考专栏:elasitc) | ⭐⭐ | 已有 ES 集群的团队 |
| rag-milvus-example | Milvus 向量数据库 | ⭐⭐ | 大规模向量检索 |
| rag-etl-pipeline-example | 数据 ETL 管道 | ⭐⭐⭐ | 需要自动化的数据导入 |
| rag-component-example | RAG 组件化开发 | ⭐⭐⭐ | 复杂业务场景 |
| rag-parallel-example | 并行检索 | ⭐⭐⭐ | 性能要求高 |
动手实操 - 构建企业知识库:
准备数据:整理你的产品手册、FAQ、技术文档(PDF/Word/Markdown)
选择向量库:建议从 pgvector 开始(最简单,PostgreSQL 直接支持)
文档切片策略:
按段落切(适合文章)
按固定长度切(适合技术文档)
按语义切(高级,需要更复杂的逻辑)
测试检索效果:用真实业务问题测试,看能否召回相关片段
调优:调整切片大小、换 Embedding 模型、加重排序(Rerank)
避坑指南:
切片大小很关键:太小会丢失上下文,太大会稀释语义。通常 500-1000 字为宜。
中文 Embedding 模型推荐:BGE-large-zh、text-embedding-v3
检索结果要加"相关性阈值",过滤掉不相关的内容
第五阶段:MCP(Model Context Protocol)
目标:掌握 模型上下文协议 ,实现 AI 与外部服务深度集成
MCP 是 Anthropic 推出的开放协议,被称为 “AI 的 USB-C 接口”。它标准化了 AI 与外部工具的连接方式,让你的工具可以被任何支持 MCP 的 AI 应用使用。
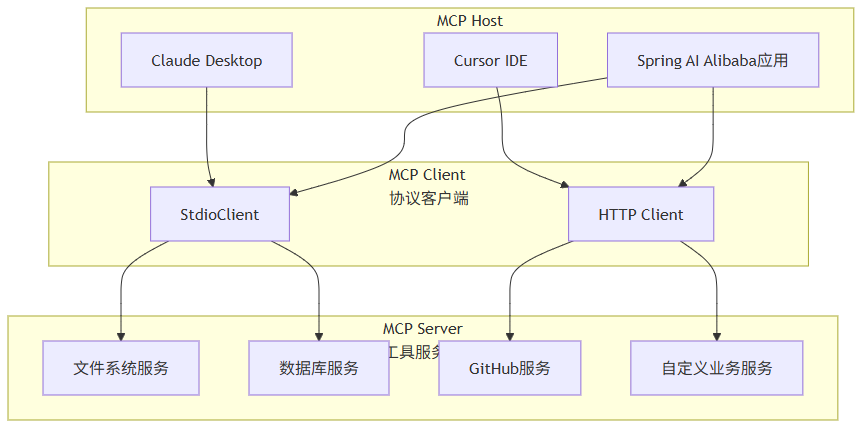
核心概念解析:
MCP 协议:基于 JSON-RPC 2.0 的通信协议,定义了 AI 如何发现、调用外部工具。
传输方式:
Stdio:本地进程通信,适合本地工具(如文件操作)
HTTP:远程服务调用,适合分布式部署
Streamable HTTP:长连接流式传输,适合实时场景
服务发现:通过 Nacos 等注册中心,实现 MCP 服务的动态发现和负载均衡。
子模块概览:
| 子模块 | 功能 | 难度 | 企业级特性 |
|---|---|---|---|
| mcp-starter-example | 注解驱动快速入门 | ⭐⭐ | 无 |
| mcp-manual-example | 第三方集成(GitHub、文件、数据库) | ⭐⭐⭐ | 基础集成 |
| mcp-build-example | 自定义构建、协议底层理解 | ⭐⭐⭐⭐ | 深度定制 |
| mcp-nacos-example | 微服务注册发现 | ⭐⭐⭐⭐ | 服务治理 |
| mcp-auth-example | 认证授权、安全集成 | ⭐⭐⭐⭐ | 企业安全 |
| mcp-config-example | 多源配置管理 | ⭐⭐⭐⭐ | 配置中心 |
动手实操:
搭建第一个 MCP 服务:把一个本地方法封装成 MCP 工具
测试 Stdio 模式:理解父子进程管道通信机制
切换到 HTTP 模式:实现远程服务调用
集成 Nacos:实现服务注册与发现(企业级必备)
添加 JWT 认证:保护你的 MCP 服务不被滥用
避坑指南:
MCP 是新兴协议,生态还在快速发展,要关注版本兼容性
Stdio 模式有平台差异,Windows 和 Linux 的进程管理不同
生产环境一定要用 HTTP + 认证,不要直接暴露本地进程
第六阶段:Graph 工作流
目标:构建复杂 AI 工作流,实现多 Agent 协作和高级编排
Graph 是 Spring AI Alibaba 的核心差异化能力,借鉴了 LangGraph 的设计理念,让你用"搭积木"的方式构建复杂的 AI 应用。
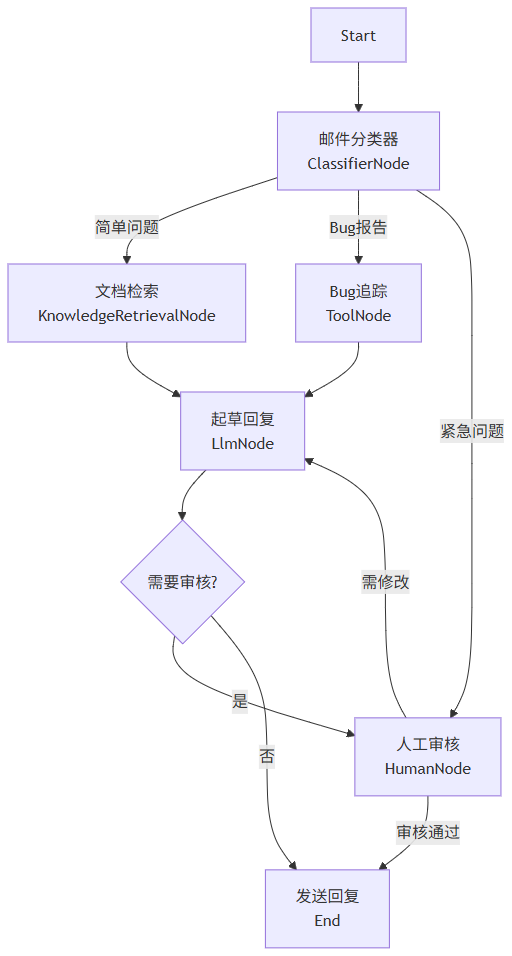
核心概念解析:
StateGraph(状态图):整个工作流的"共享内存",每个节点可以读写状态,实现数据流转。
节点类型:
LlmNode:调用大模型生成内容
ToolNode:调用外部工具
ConditionNode:条件判断,实现分支逻辑
HumanNode:人工介入,等待用户输入
持久化与恢复:工作流可以暂停、保存状态,稍后从断点恢复(Human-in-the-Loop 的基础)。
子模块概览:
| 子模块 | 功能 | 难度 | 学习重点 |
|---|---|---|---|
| workflow-writing-assistant | 智能写作助手 | ⭐⭐ | 基础流程编排 |
| workflow-review-classifier | 工作流审查分类 | ⭐⭐⭐ | 条件分支 |
| react | ReAct 模式 | ⭐⭐⭐ | 推理+行动循环 |
| chatflow | 对话流程编排 | ⭐⭐⭐ | 多轮对话管理 |
| human-node | 人工介入节点 | ⭐⭐⭐⭐ | Human-in-the-Loop |
| parallel-node | 并行处理节点 | ⭐⭐⭐⭐ | 性能优化 |
| reflection | 反射反思机制 | ⭐⭐⭐⭐ | 自我优化 |
| multiagent-openmanus | 多 Agent 协作 | ⭐⭐⭐⭐⭐ | 复杂协作 |
| product-analysis-graph | 产品分析工作流 | ⭐⭐⭐⭐⭐ | 业务场景实战 |
代码示例 - 智能写作助手:
@Bean public Graph<WorkFlowState> writingAssistantGraph() { // 定义节点:摘要生成器 Node summarizerNode = new LlmNode(summarizer); // 分类器:判断质量是否达标 Node classifierNode = new ConditionNode(feedbackClassifier); // 改写器:优化内容 Node reworderNode = new LlmNode(reworder); // 标题生成器 Node titleNode = new LlmNode(titleGenerator); // 构建图:摘要 -> 分类 -> [改写或标题] -> 标题 return GraphSpec.builder(summarizerNode) .transitionTo(classifierNode) .conditionalTransitionFrom(classifierNode, (state) -> state.feedback == "positive" ? reworderNode : summarizerNode) .transitionTo(titleNode) .build(); }
动手实操:
从 workflow-writing-assistant 入手:理解"节点+边"的基本模式
添加 HumanNode:实现人工审核环节,体验"人在回路"
实现并行节点:同时调用多个工具,汇总结果(如同时查天气和新闻)
尝试 multiagent-openmanus:理解多 Agent 如何分工协作
设计自己的工作流:结合业务场景,画出流程图再编码
避坑指南:
状态管理是关键:不要存太多数据,也不要丢失关键上下文
循环要设置终止条件:避免无限循环消耗 Token
错误处理:每个节点都可能失败,要考虑降级策略
学习路线图总览(个人建议)
入门阶段 (1-5天) ├── Hello World (⭐) → 建立信心,验证环境 └── 多模型对话 (⭐⭐) → 理解模型差异,掌握配置 进阶阶段 (6-14天) ├── 工具调用 (⭐⭐) → AI 开始"干活" └── RAG 知识库 (⭐⭐⭐) → AI 懂"你的业务" 高级阶段 (15-35天) ├── MCP 协议集成 (⭐⭐⭐⭐) → 标准化工具生态 └── Graph 工作流 (⭐⭐⭐⭐⭐) → 构建复杂智能体
学习建议
时间规划(总计 25-35 天)
| 阶段 | 时间 | 每日建议 | 关键产出 |
|---|---|---|---|
| Hello World | 1-2 天 | 2-3 小时 | 跑通第一个 AI 应用 |
| 多模型对话 | 2-3 天 | 2-3 小时 | 掌握多模型切换 |
| 工具调用 | 3-4 天 | 3 小时 | 实现 3+ 个自定义工具 |
| RAG | 5-7 天 | 3-4 小时 | 构建企业知识库原型 |
| MCP | 5-7 天 | 3-4 小时 | 发布第一个 MCP 服务 |
| Graph | 7-10 天 | 4 小时 | 设计复杂工作流 |
学习方法
1. 先跑通,再读懂
每个模块先按照 README 运行起来,观察输出结果
然后逐行阅读源代码,理解"为什么这样写"
最后尝试修改参数,观察变化
2. 边学边实践
每个阶段完成后,结合自己的业务场景做小项目
例如:工具调用阶段,可以做一个"智能运维助手"调用你的监控 API
RAG 阶段,可以整理你们的技术文档做知识库
3. 做好笔记
记录配置要点(yaml 文件是关键)
总结各模块的适用场景(什么情况下用什么)
整理常见错误和解决方案
4. 善用社区资源
阿里云开发者社区有大量实战案例
快速开始命令
环境准备
# 设置 API Key(必须) export AI_DASHSCOPE_API_KEY=your_api_key_here # 克隆项目 git clone https://github.com/alibaba/spring-ai-alibaba-examples.git cd spring-ai-alibaba-examples/examples-main
启动示例
# Hello World(第1阶段) mvn -pl spring-ai-alibaba-helloworld spring-boot:run # 多模型对话(第2阶段) mvn -pl spring-ai-alibaba-chat-example spring-boot:run # 工具调用(第3阶段) mvn -pl spring-ai-alibaba-tool-calling-example spring-boot:run # RAG(第4阶段) mvn -pl spring-ai-alibaba-rag-example spring-boot:run # MCP(第5阶段) mvn -pl spring-ai-alibaba-mcp-example spring-boot:run # Graph(第6阶段) mvn -pl spring-ai-alibaba-graph-example spring-boot:run
学习目标检查清单
基础 ✅
配置好 Java 17+ 和 Maven
获取阿里云 DashScope API Key(新用户有免费额度)
跑通 Hello World 示例,看到 AI 回复
理解 ChatClient 和 ChatModel 的区别(前者友好,后者灵活)
进阶 ✅
能切换不同模型(OpenAI、ZhiPu、Moonshot)并对比效果
理解工具调用机制(AI 决定调用→你的代码执行→AI 生成回复)
能自定义工具函数(至少实现天气查询、计算器、数据库查询)
构建简单的 RAG 知识库(能基于你的文档回答问题)
高级 ✅
理解 MCP 协议和工作原理(Stdio vs HTTP,服务发现)
能配置 MCP 微服务集成(Nacos 注册中心)
构建基于 Graph 的工作流(至少包含 3 个节点)
实现多 Agent 协作系统(如:一个 Agent 负责查询,一个负责总结)
常见问题
Q1: 需要学习哪些前置知识?
✅ Java 17+ 基础(Lambda、Stream API)
✅ Spring Boot 基本使用(自动配置、REST API)
✅ Maven 构建工具
❌ 不需要:Python、机器学习理论、深度学习框架
Q2: 需要购买阿里云服务吗?
✅ 可以使用免费额度(新用户通常有 100 万 token 免费额度)
✅ 也可以使用本地模型(Ollama 运行 Llama、DeepSeek 等)
✅ 或者使用其他平台的 API Key(OpenAI、Moonshot 等)
Q3: 遇到 API 调用失败怎么办?
检查 AI_DASHSCOPE_API_KEY 是否正确设置(echo $AI_DASHSCOPE_API_KEY)
查看网络连接是否正常(能否访问阿里云)
查看日志输出(开启 DEBUG 模式:logging.level.org.springframework.ai: DEBUG)
检查模型名称是否正确(qwen-plus vs qwen-turbo)
Q4: 学习过程中卡住了怎么办?
先确保示例代码能原样运行,不要一上来就改代码
查看 GitHub Issues,看是否有人遇到类似问题
降低复杂度:如果 Graph 工作流看不懂,先回去巩固 Tool Calling
