从零入门!MySQL 约束、范式设计与联合查询核心精讲
【前言】
数据库是后端开发的基石,而约束、范式设计与联合查询是构建稳定、高效数据库的核心能力,本文将从基础的数据库约束讲起,再到三大范式设计,最后梳理多表联合查询的核心场景,帮你把零散 知识点 串成体系,快速掌握 MySQL 数据库设计与查询的关键逻辑。
一、约束
1.数据库约束
针对表的内容做出限制,用于确保数据的准确性和可靠性;
创建表的时候确定出来,跟随建表语句,一起被设置到数据库服务器中;
约束可以是数据类型,值范围,唯一性,非空等规则,确保数据的正确性和相容性
2.约束类型
| 类型 | 说明 |
|---|---|
| NOT NULL 非空约束 | 指定非空约束的列不能存储NULL值 |
| DEFALUT 默认约束 | 当没有给列赋值时使用的默认值 |
| UNIQUE 唯一约束 | 指定唯一约束的列每行数据必须有唯一的值 |
| PRIMARY KEY 主键约束 | NOT NULL 和 UNIQUE 的结合,可以指定一个列或多个列,有助于防止数据重复和提高数据的查询性能 |
| POREIGN KEY 外键约束 | 外键约束是一种关系约束,用于定义两个表之间的关联关系,可以确保数据的完整性和一致性 |
| CHECK 约束 | 用于限制列或数据在数据库表中的值,确保数据准确性和可靠性 |
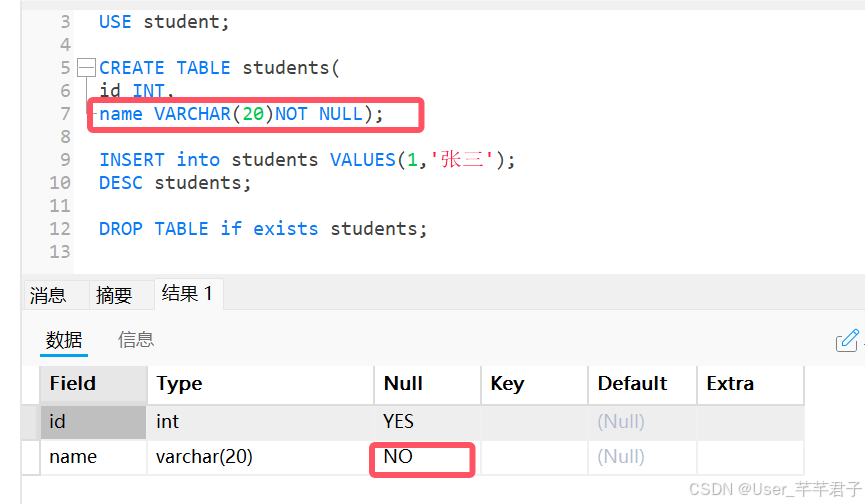
2.1 NOT NULL 非空约束
定义表的某列不允许为NULL时,添加非空约束;
如下图:定义学生名,约束不能为NULL
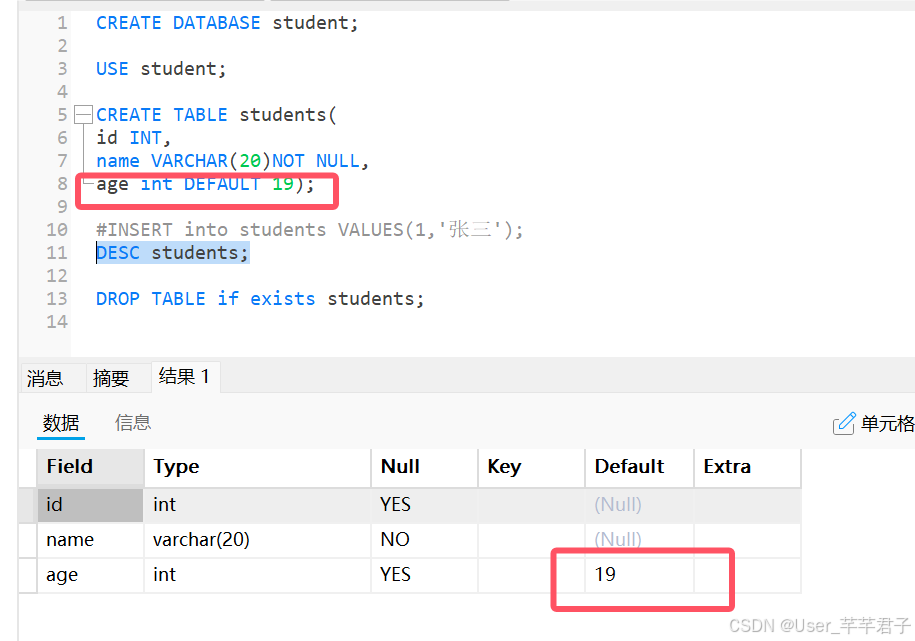
2.2 DEFALUT 默认约束
DEFALUT 约束用于向列中插入默认值,如果没有为列设置值,那么将会将默认值设置到该列;
没有设置默认约束时,列为NULL
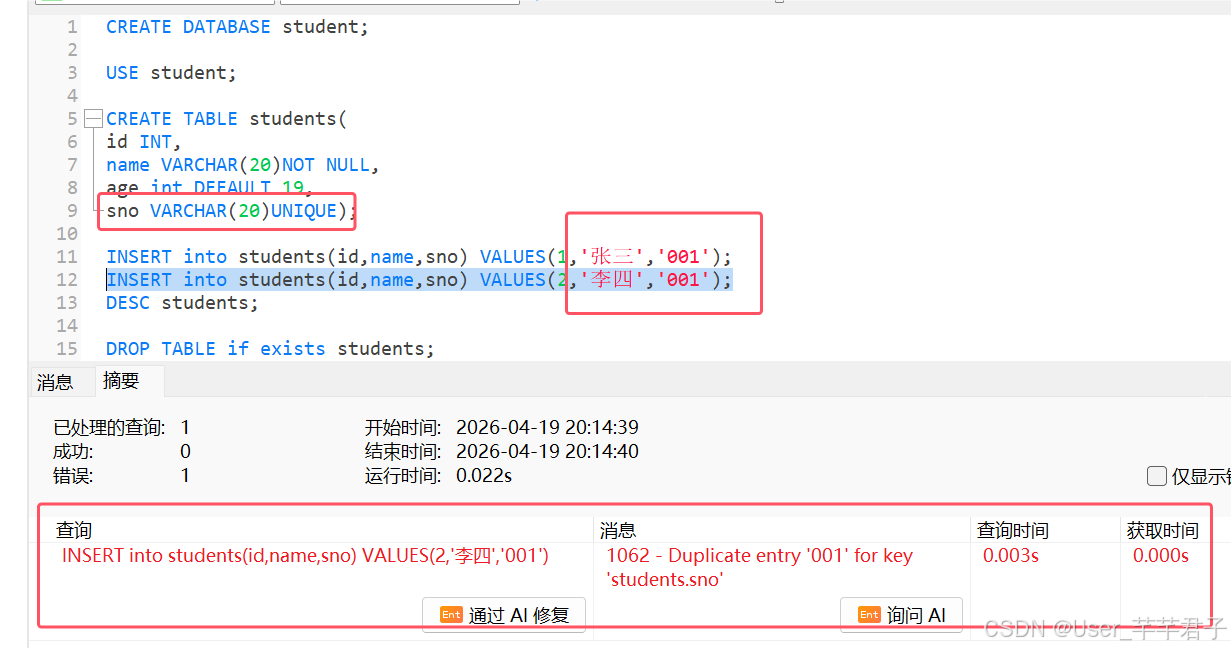
2.3 UNIQUE 唯一约束
唯一约束的列,该列的值在所有记录中不能重复
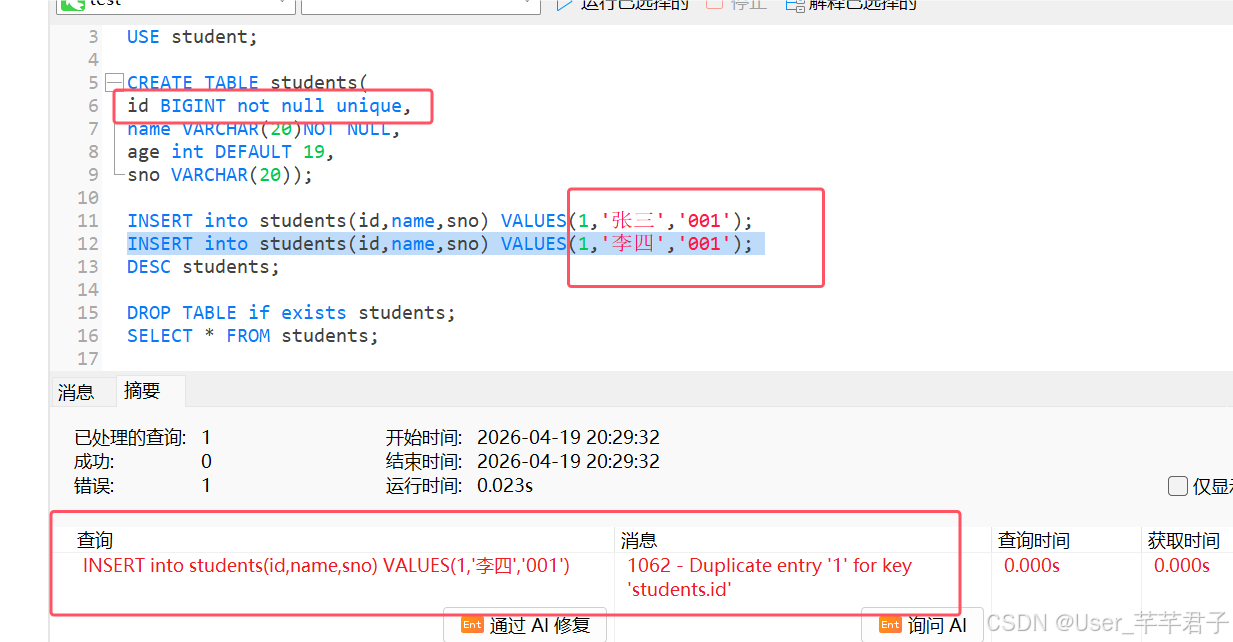
如下图:设置唯一约束后,这个学号重复就会报错
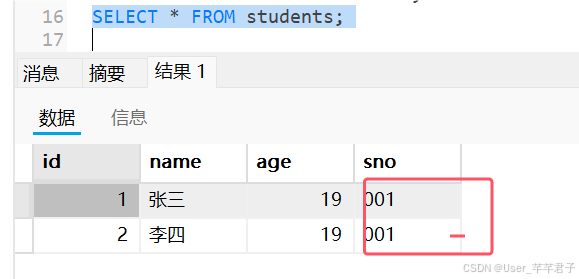
不设置这个唯一约束,就可以正常添加
2.4 PRIMARYKEY主键约束
主键约束就是NOT NULL + NUIQUE;
必须包含唯一的值,且不能包含NULL;
每个表只能有一个主键,可以由单个列或多个列组成;
主键列建议使用BIGINT类型
添加非空和唯一约束后,key列显示PRI表示主键
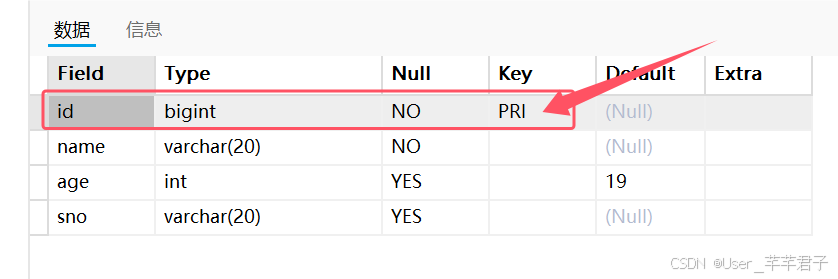
id列重复时,会发生主键冲突
通常把主键列设置为自动增长,让数据库维护主键值;
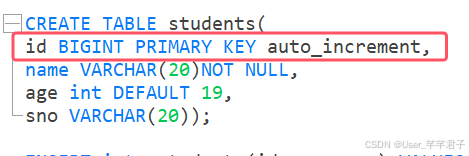
插入数据时,不设置主键列的值,也就是为NULL;
如果某条记录写⼊失败,新⽣成的主键值将会作废;
主键值可以不连续;
由多个列组成的主键称为复合主键
2.5 FOREIGNKEY外键约束
外键用于定义主表和从表之间的关系;
外键约束定义在从表的列上,主表关联的列必须是主键或唯一约束;
当定义外键后,要求从表中的外键列数据必须在主表的主键或唯一列存在或为null;
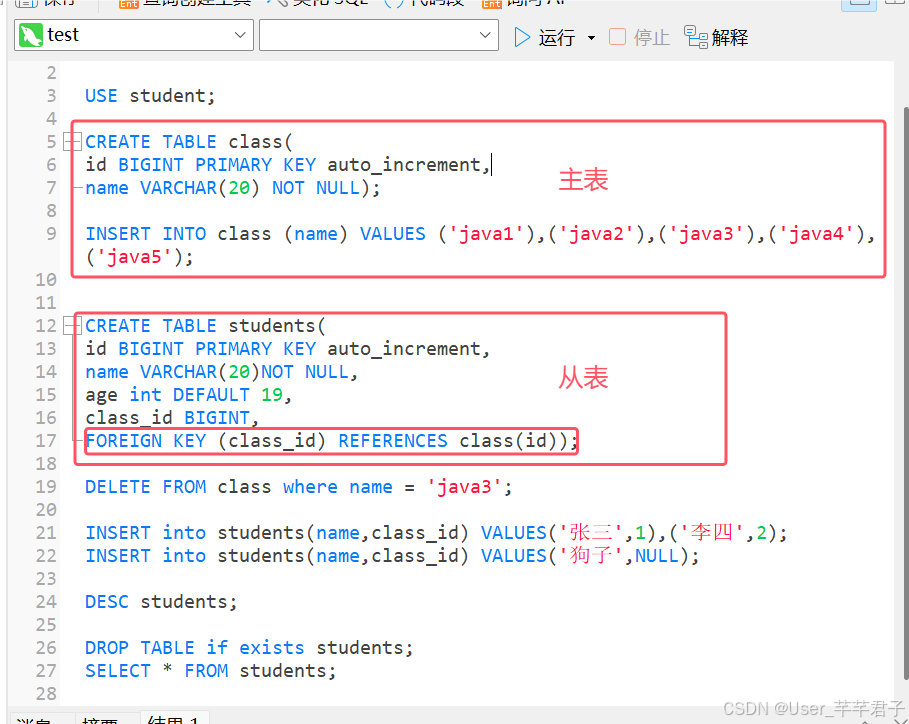
插入班级id为NULL的记录,可以成功,说明没有分配班级,但不能插入没有的班级id;
删除主表的某条记录时,从表不能有对该记录的引用;
删除主表时,要先删除从表;
2.6 CHECK约束(MySQL8版本)
可以应⽤于⼀个或多个列,⽤于限制列中可接受的数据值,从⽽确保数据的完整性和准确性。(根据需要灵活定义)
二、数据库设计
1.三大范式
数据库的范式是⼀组规则。在设计关系数据库时,遵从不同的 规范 要求,设计出合理的关系型数据库,这些不同的规范要求被称为不同的范式。
1.1第一范式
定义
数据库的每一列都是不可分割的原子数据项,而不能是集合,数组,对象等非原子数据;
在关系型数据库的设计中,满足第一范式是对关系模式的基本要求。不满足第一范式的数据库就不能被称为关系数据库
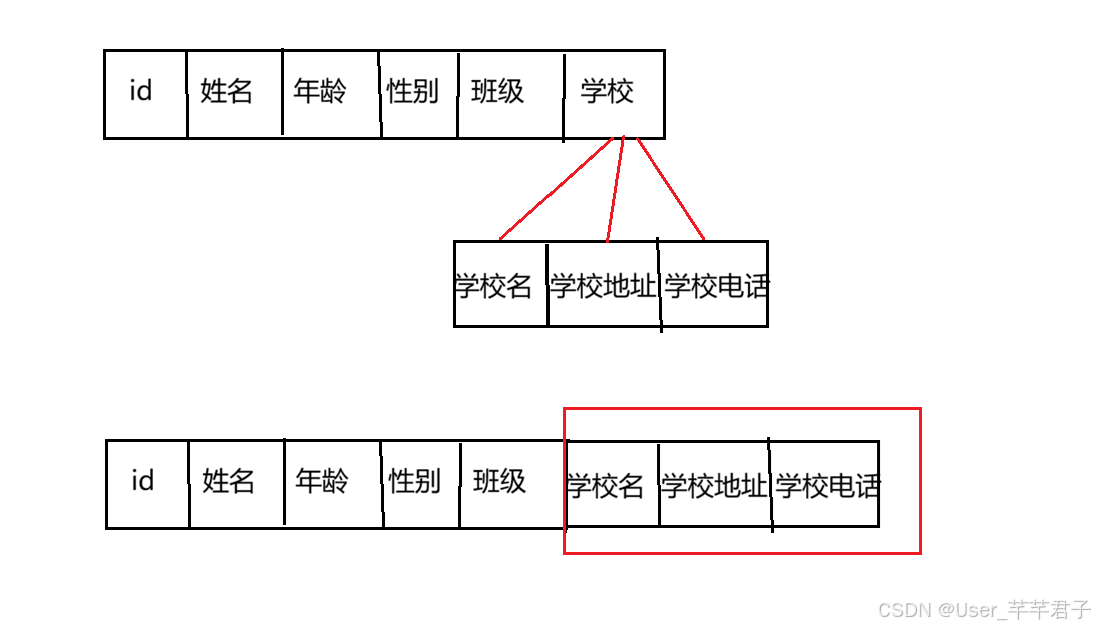
eg:定义一个学生表,分为学生信息和学校信息
学校是一个对象,可以继续拆分,不满足第一范式;
学校信息包含在一行中,每一行都不能拆分,满足第一范式
1.2 第二范式
定义
在满足第一范式的基础上,不存在非关键字段对任意候选键的部分函数依赖。存在于表中定义了复合主键的情况下
复合主键:一个表只能有一个主键,但这一个主键可以包含一个列,也可以包含多个列;
完全函数依赖:通过整个主键,确定一个数据;
部分函数依赖:通过主键中的一部分,就能确定一个数据;
候选键:复合主键中的列;
非关键字段:除候选键之外剩下的列
eg:学号+课程名作为复合主键,都是候选键–>确定一条记录(完全依赖)
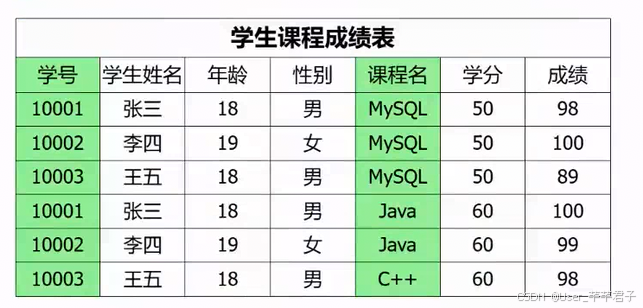
一张表中的某个列,不能只被主键的一部分确定出来;
实际开发中,大多数表都是单一的主键,天然遵循第二范式
不满足第二范式时出现的问题
数据冗余;
更新异常;
插入异常;
删除异常;
1.3 第三范式
在满足第二范式的基础上,不存在非关键字段,对任⼀候选键的传递依赖。(就是消灭传递依赖)
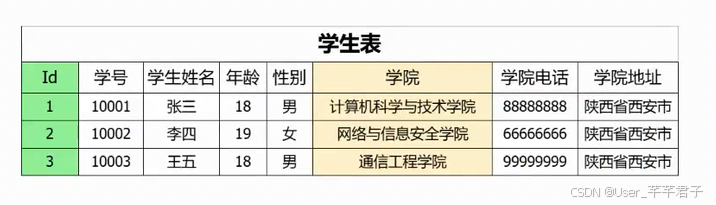
eg:
学院–>学院电话和地址;
id–>学院;
so:id–>学院电话和地址
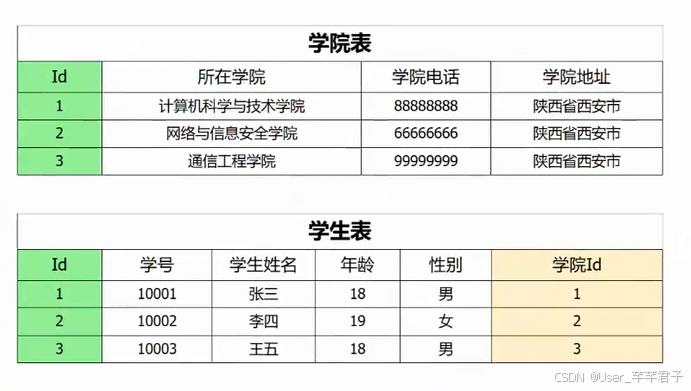
拆成两张表,就不存在传递依赖了
【总结】
第一范式:要求列不可拆分;(不要把多个内容合并在一起)
第二范式:要消灭部分依赖;(注意有复合主键的情况)
第三范式:要消灭依赖传递
2.设计过程
从现实业务中抽象得到概念类
概念类是从现实世界中抽象出来的,在需求分析阶段就需要确定下来◦
类对应了数据库设计中的实体,实体对应了数据库中的表◦
类中的属性对应实体中的属性,实体的属性对应了表中的列
确定实体与实体之间的关系,并画出E-R画,⽅便项⽬参与⼈员理解与沟通
根据E-R图完成SQL语句的编号并创建数据库
表与表之间的关系
一对一;
一对多;
多对多;
没关系
三、联合查询
联合查询的表,需要有一定关系(一对一,一对多…)
1.笛卡尔积
笛卡尔积结果的列数就是两个表列数之和;
笛卡尔积结果的行数就是两个表行数之积;
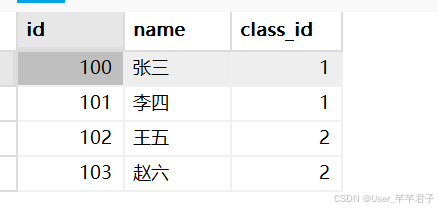

顺序可能不一致,除非使用order by
笛卡尔积排列组合把所有情况列出来,其中包含无效数据
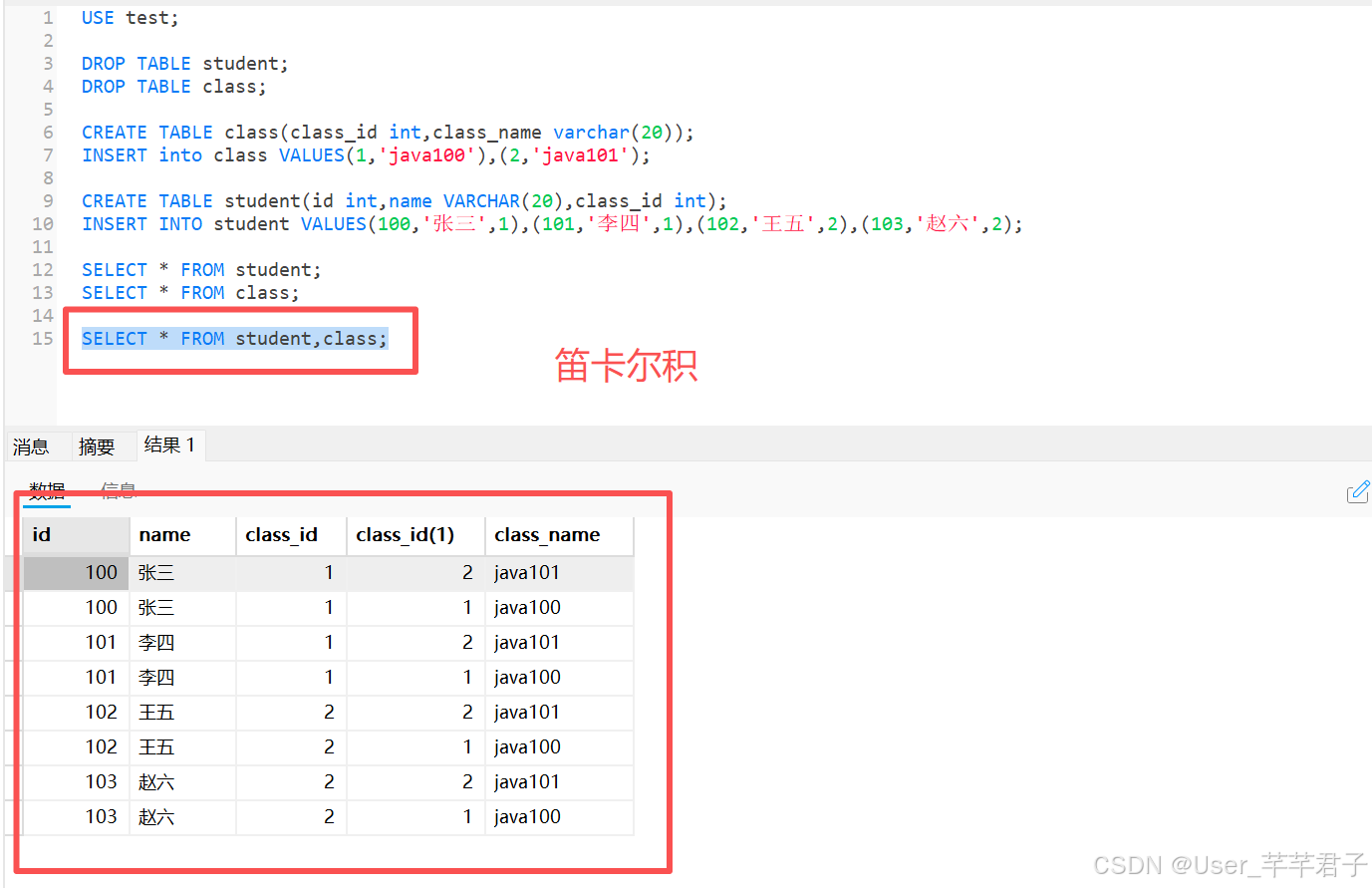
连接条件:两个表进行笛卡尔积的时候,其中对应列的值相同,筛选出来作为合理数据;(成员访问运算符)
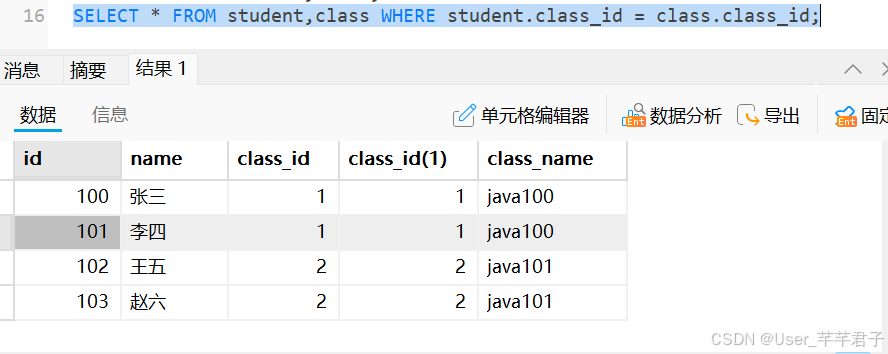
【总结】多表联合查询
1.先进行笛卡尔积;
2.通过连接条件,进行筛选;
3.根据实际需求场景,进一步添加其他条件/order by/limit
4.针对列进行筛选/计算/分组/聚合
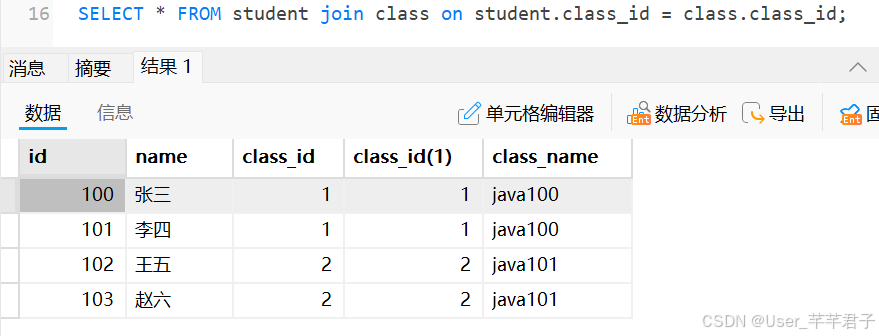
2.内连接
上面的多表查询也是在进行内连接
join on
3.外连接
左外连接:返回左表的所有记录和右表中匹配的记录.如果右表中没有匹配的记录,则结果集中对应字段会显⽰为NULL。
右外连接:与左外连接相反,返回右表的所有记录和左表中匹配的记录。如果左表中没有匹配的记录,则结果集中对应字段会显⽰为NULL。
全外连接:结合了左外连接和右外连接的特点,返回左右表中的所有记录。如果某⼀边表中没有匹配的记录,则结果集中对应字段会显⽰为NULL。
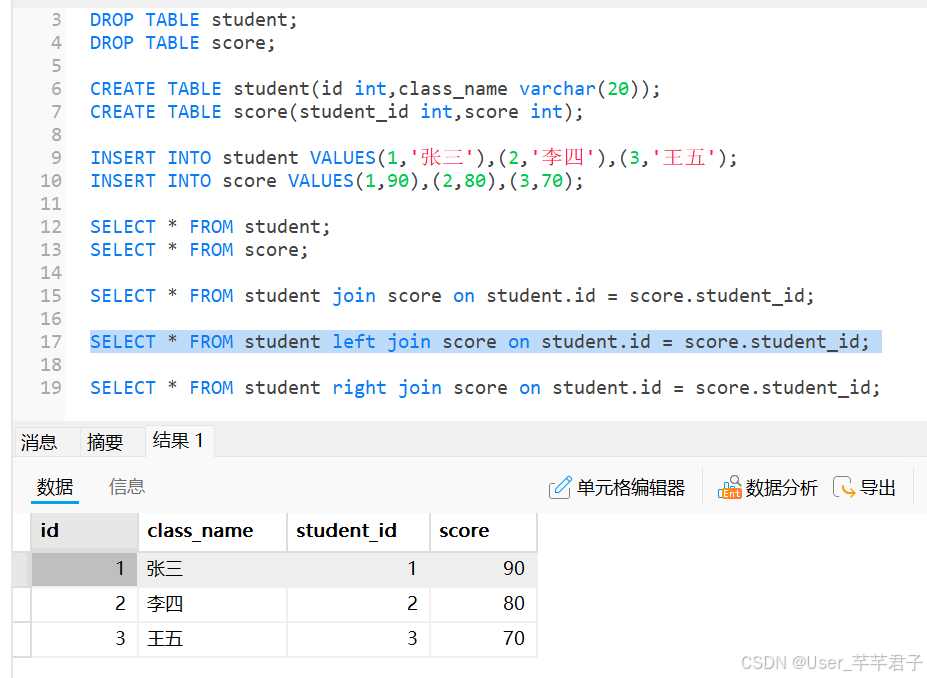
以左侧表为基准,把左侧表中所有的数据都列出来,至于右侧表没有的部分,填成null
4.自连接
自连接是自己与自己取笛卡尔积,可以把行转化成列,在查询的时候可以使⽤where条件对结果进⾏过滤,或者说实现⾏与⾏之间的⽐较。(在做表连接时为表起不同的别名。)
5.子查询(少用)
子查询是把⼀个SELECT语句的结果当做别⼀个SELECT语句的条件,也叫嵌套查询
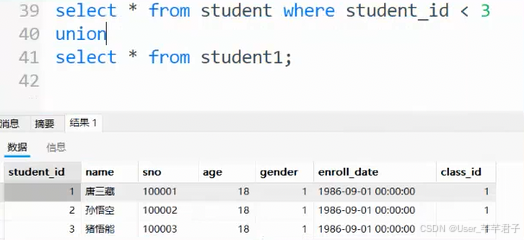
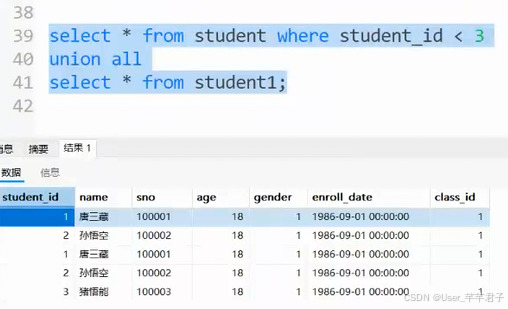
6.合并查询(并列关系)
把多个SQL的查询结果,合并成一个结果 集合 ;
确保合并的两组查询结果,列的个数/类型/要匹配
union : 求并集
==union all : ==
四、总结
本文系统梳理了 MySQL 数据库三大核心模块:数据库约束是保障数据完整性的第一道防线,从非空、默认、唯一到主键、外键、CHECK 约束,全方位避免无效、矛盾数据入库;三大范式是优化数据库结构的关键,通过减少数据冗余、规避更新 / 插入 / 删除异常,帮你设计出更合理、可维护的表结构;联合查询则覆盖了笛卡尔积、内连接、外连接、自连接与子查询的用法,让你能高效实现多表关联查询,写出性能更优的 SQL 语句,为后续复杂业务场景的数据库开发与优化打下坚实基础。
